In March 2022, as Western nations imposed unprecedented sanctions following Russia’s invasion of Ukraine, Zoltan Pozsar published a series of dispatches that would become some of the most discussed pieces in financial markets that year. The core thesis was stark: we were witnessing the birth of “Bretton Woods III,” a fundamental shift in how the global monetary system operates. Nearly three years later, with more data on de-dollarization trends, commodity market dynamics, and structural changes in global trade, it’s worth revisiting this framework.
I first heard of Pozsar at Credit Suisse during the 2019 repo market disruptions and the March 2020 funding crisis, when his framework explained market dynamics in a way I have never seen it before. Before joining Credit Suisse as a short-term rate strategist, Pozsar spent years at the Federal Reserve (where he created the map of the shadow banking system, which prompted the G20 to initiate regulatory measures in this area) and the U.S. Treasury. His work focuses on what he calls the “plumbing” of financial markets, the often-overlooked mechanisms through which money actually flows through the system. His intellectual approach draws heavily from Perry Mehrling’s “money view,” which treats money as having four distinct prices rather than being a simple unit of account.
Pozsar’s Bretton Woods III framework rests on a straightforward distinction. “Inside money” refers to claims on institutions: Treasury securities, bank deposits, central bank reserves. “Outside money” refers to commodities like gold, oil, wheat, metals that have intrinsic value independent of any institution’s promise.
Bretton Woods I (1944-1971) was backed by gold, outside money. The U.S. dollar was convertible to gold at a fixed rate, and other currencies were pegged to the dollar. When this system collapsed in 1971, Bretton Woods II emerged: a system where dollars were backed by U.S. Treasury securities, inside money. Countries accumulated dollar reserves, primarily in the form of Treasuries, to support their currencies and facilitate international trade.
Pozsar’s argument: the moment Western nations froze Russian foreign exchange reserves, the assumed risk-free nature of these dollar holdings changed fundamentally. What had been viewed as having negligible credit risk suddenly carried confiscation risk. For any country potentially facing future sanctions, the calculus of holding large dollar reserve positions shifted. Hence Bretton Woods III: a system where countries increasingly prefer holding reserves in the form of commodities and gold, outside money that cannot be frozen by another government’s decision.
To understand Pozsar’s analysis, we need to understand his analytical framework. Perry Mehrling teaches that money has four prices: (1) Par: The one-for-one exchangeability of different types of money. Your bank deposit should convert to cash at par. Money market fund shares should trade at $1. When par breaks, as it did in 2008 when money market funds “broke the buck,” the payments system itself is threatened. (2) Interest: The price of future money versus money today. This is the domain of overnight rates, term funding rates, and the various “bases” (spreads) between different funding markets. When covered interest parity breaks down and cross-currency basis swaps widen, it signals stress in the ability to transform one currency into another over time. (3) Exchange rate: The price of foreign money. How many yen or euros does a dollar buy? Fixed exchange rate regimes can collapse when countries lack sufficient reserves, as happened across Southeast Asia in 1997. (4) Price level: The price of commodities in terms of money. How much does oil, wheat, or copper cost? This determines not just headline inflation but feeds through into the price of virtually everything in the economy.
Central banks have powerful tools for managing the first three prices. They can provide liquidity to preserve par, influence interest rates through policy, and intervene in foreign exchange markets. But the fourth price, the price level, particularly when driven by commodity supply shocks, is far harder to control. As Pozsar puts it: “You can print money, but not oil to heat or wheat to eat.”
Pozsar’s contribution was to extend Mehrling’s framework into what he calls the “real domain,” the physical infrastructure underlying commodity flows. For each of the three non-commodity prices of money, there’s a parallel in commodity markets: (1) Foreign exchange ↔ Foreign cargo: Just as you exchange currencies, you exchange dollars for foreign-sourced commodities. (2) Interest (time value of money) ↔ Shipping: Just as lending has a time dimension, moving commodities from port A to port B takes time and requires financing. (3) Par (stability) ↔ Protection: Just as central banks protect the convertibility of different money forms, military and diplomatic power protects commodity shipping routes.
This mapping reveals something important: commodity markets have their own “plumbing” that works parallel to financial plumbing. And when this real infrastructure gets disrupted, it creates stresses that purely monetary policy cannot resolve.
One of the most concrete examples in Pozsar’s March 2022 dispatches illustrates this intersection between finance and physical reality. Consider what happens when Russian oil exports to Europe are disrupted and must be rerouted to Asia. Previously, Russian oil traveled roughly 1-2 weeks from Baltic ports to European refineries on Aframax carriers (ships carrying about 600,000 barrels). The financing required was relatively short-term, a week or two. Post-sanctions, the same oil must travel to Asian buyers. But the Baltic ports can’t accommodate Very Large Crude Carriers (VLCCs), which carry 2 million barrels. So the oil must first be loaded onto Aframax vessels, sailed to a transfer point, transferred ship-to-ship to VLCCs, then shipped to Asia, a journey of roughly four months.
The same volume of oil, moved the same distance globally, now requires: (a) More ships (Aframax vessels for initial transport plus VLCCs for long-haul). (b) More time (4 months instead of 1-2 weeks). (c) More financing (commodity traders must borrow for much longer terms). (d) More capital tied up by banks (longer-duration loans against volatile commodities).
Pozsar estimated this rerouting alone would encumber approximately 80 VLCCs, roughly 10% of global VLCC capacity, in permanent use. The financial implication: banks’ liquidity coverage ratios (LCRs) increase because they’re extending more term credit to finance these longer shipping durations. When commodity trading requires more financing for longer durations, it competes with other demands for bank balance sheet. If this happens simultaneously with quantitative tightening (QT), when the central bank is draining reserves from the system, funding stresses become more likely. As Pozsar noted: “In 2019, o/n repo rates popped because banks got to LCR and they stopped lending reserves. In 2022, term credit to commodity traders may dry up because QT will soon begin in an environment where banks’ LCR needs are going up, not down.”
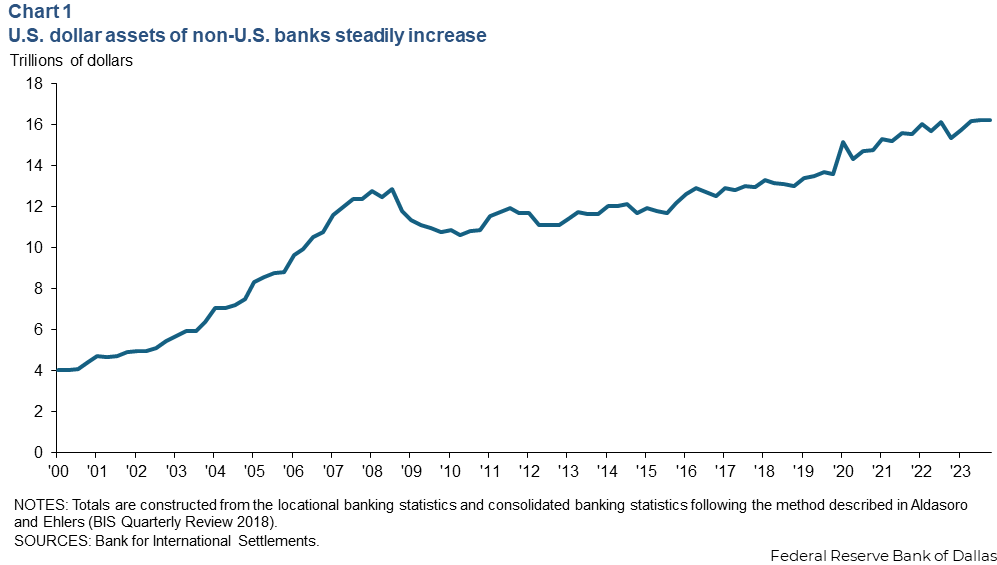
One aspect of the framework that deserves more attention relates to dollar funding for non-U.S. banks. According to recent Dallas Fed research, banks headquartered outside the United States hold approximately $16 trillion in U.S. dollar assets, comparable in magnitude to the $22 trillion held by U.S.-based institutions. The critical difference: U.S. banks have access to the Federal Reserve’s emergency liquidity facilities during periods of stress. Foreign banks do not have a U.S. dollar lender of last resort. During the COVID-19 crisis, the Fed expanded dollar swap lines to foreign central banks precisely to address this vulnerability, about $450 billion, roughly one-sixth of the Fed’s balance sheet expansion in early 2020. The structural dependency on dollar funding creates ongoing vulnerabilities. When dollars become scarce globally, whether due to Fed policy tightening, shifts in risk sentiment, or disruptions in commodity financing, foreign banks face balance sheet pressures that can amplify stress. The covered interest parity violations that Pozsar frequently discusses reflect these frictions: direct dollar borrowing and synthetic dollar borrowing through FX swaps theoretically should cost the same, but in practice, significant basis spreads persist.
Continue reading Pozsar’s Bretton Woods III: Three Years Later [2/2]
{kind=link}
{kind=link}
{kind=link}