# Beyond Vector Search: Why LLMs Need Episodic Memory
**Author:** Philipp D. Dubach | **Published:** January 9, 2026 | **Updated:** February 23, 2026
**Categories:** AI
**Keywords:** LLM memory architecture, episodic memory AI, knowledge graph LLM memory, vector database limitations RAG, KV cache optimization transformer
## Key Takeaways
- Context windows grew to 200K tokens (Claude) and 1M (Gemini), but bigger windows are not memory because they lack persistence, temporal awareness, and the ability to update facts across sessions
- EM-LLM segments conversation into episodes using surprise detection, and its event boundaries correlate with where humans perceive breaks in experience
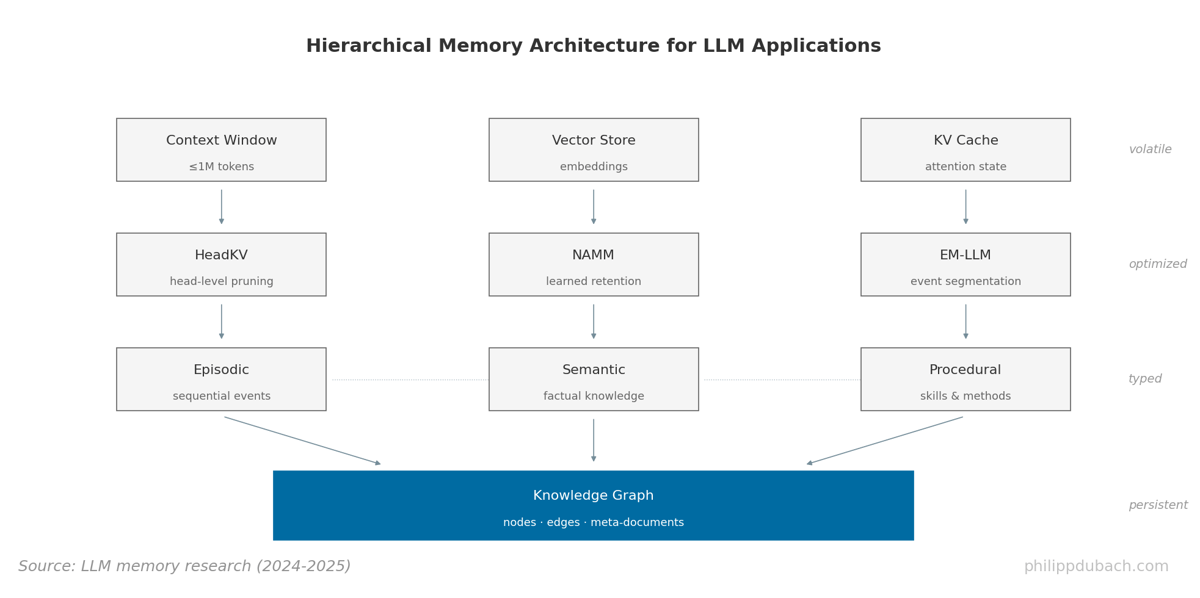
- HeadKV found you can discard 98.5% of a transformer's key-value cache by keeping only the attention heads that matter for memory, with almost no quality loss
- Mem0 reports 80-90% token cost reduction with a 26% quality improvement by replacing raw chat history with structured memory, though the claim is unvalidated
---
You've seen this message before. Copilot pausing; In long sessions, it happens often enough that I started wondering what's actually going on in there. Hence this post.
The short answer: context windows grew larger. [Claude handles 200K tokens](https://platform.claude.com/docs/en/build-with-claude/context-windows), [Gemini claims a million](https://gemini.google/overview/long-context/). But bigger windows aren't memory. They're a larger napkin you throw away when dinner's over.
For som time I was convinced that vector databases would solve this. Embed everything, store it geometrically, retrieve by similarity. Elegant in theory. Try encoding "first we did X, then Y happened, which caused Z." Sequences don't live naturally in vector space. Neither do facts that change over time. Your database might confidently tell you Bonn is Germany's capital if you fed it the wrong decade of documents.
What caught my attention is [EM-LLM](https://openreview.net/forum?id=BI2int5SAC). The approach is basically "what if we just copied how brains do it?" They segment conversation into episodes using surprise detection; when something unexpected happens, that's a boundary. Retrieval pulls not just similar content but temporally adjacent content too. You don't just remember what you're looking for. You remember what happened next. Their event boundaries actually correlate with where humans perceive breaks in experience. Either a coincidence or we're onto something.
Knowledge graphs are the other path. [Persona Graph](https://github.com/saxenauts/persona) treats memory as user-owned, with concepts as nodes. The connection between "volatility surface" and "Lightning McQueen" exists in my head (for some reason) but probably not yours. A flat embedding can't capture that your graph is different from mine. [HawkinsDB](https://github.com/HawkinsRAG/HawkinsDB) pulls from Thousand Brains theory. [Letta](https://docs.letta.com/) just ships, production-ready blocks you can use today. [OpenMemory](https://github.com/CaviraOSS/OpenMemory) goes further, separating emotional memory from procedural from episodic, with actual decay curves instead of hard timeouts. [Mem0](https://mem0.ai/blog/llm-chat-history-summarization) reports 80-90% token cost reduction while quality goes up 26%. I can't validate the claim, but if it holds, that's more than optimization.
[HeadKV](https://github.com/FYYFU/HeadKV/) figured out that attention heads aren't created equal: some matter for memory, most don't. Throw away 98.5% of your key-value cache, keep the important heads, lose almost nothing. [Sakana AI](https://arxiv.org/abs/2410.13346) went weirder: tiny neural networks that decide per-token whether to remember or forget, evolved rather than trained. Sounds like it shouldn't work. Apparently works great.
Here's what I keep coming back to: in any mature system, most of the graph will be memories of memories. You ask me my favorite restaurants, I think about it, answer, and now "that list I made" becomes its own retrievable thing. Next time someone asks about dinner plans, I don't re-derive preferences from first principles. I remember what I concluded last time. Psychologists say [this is how human recall actually works](https://www.taylorfrancis.com/books/mono/10.4324/9781315755854/working-memory-pierre-barrouillet-valérie-camos); you're not accessing the original, you're accessing the last retrieval. Gets a little distorted each time.
Should the model control its own memory? Give it a "remember this" tool? I don't think so, not yet. [These things are overconfident](https://arxiv.org/abs/2505.02151). Maybe that changes. For now, memory probably needs to happen around the model, not through it. Eventually some learned architecture will make all this scaffolding obsolete. Train memory into the weights directly. I have no idea what that looks like. Sparse mixture of experts with overnight updates? Some forgotten recurrent trick? Right now it's all duct tape and cognitive science papers.
---
## Frequently Asked Questions
### Why aren't bigger context windows true LLM memory?
Context windows grew larger (Claude handles 200K tokens, Gemini claims a million), but bigger windows aren't memory. They're a larger napkin you throw away when dinner's over. True memory requires persistence across sessions, temporal awareness, and the ability to update facts over time, none of which context windows provide.
### Why do vector databases fail for sequential conversation data?
Vector databases embed content geometrically and retrieve by similarity, but sequences don't live naturally in vector space. Try encoding "first we did X, then Y happened, which caused Z." Additionally, facts that change over time cause problems: your database might confidently tell you Bonn is Germany's capital if you fed it the wrong decade of documents.
### What is EM-LLM and how does it implement episodic memory?
EM-LLM segments conversation into episodes using surprise detection: when something unexpected happens, that's a memory boundary. Retrieval pulls not just similar content but temporally adjacent content too. You don't just remember what you're looking for; you remember what happened next. Their event boundaries actually correlate with where humans perceive breaks in experience.
### Should you give an LLM control of its own memory?
Not yet. LLMs are overconfident, making them unreliable judges of what to remember. Memory probably needs to happen around the model, not through it. Eventually some learned architecture will make this scaffolding obsolete by training memory into the weights directly.
---
*Philipp D. Dubach — [http://philippdubach.com/](http://philippdubach.com/) — 2026*