Anthropic just released Claude Opus 4.6, the latest frontier AI model in the Claude family. It’s a significant upgrade over Opus 4.5 and arguably the most agentic-focused LLM release we’ve seen from any lab this year.
Key upgrades: better agentic AI coding capabilities (plans more carefully, sustains longer tasks, catches its own mistakes), a 1M token context window (a first for Opus-class models), and 128K output tokens. Pricing holds at $5/$25 per million tokens.
LLM Benchmark Results: How Claude Opus 4.6 Compares
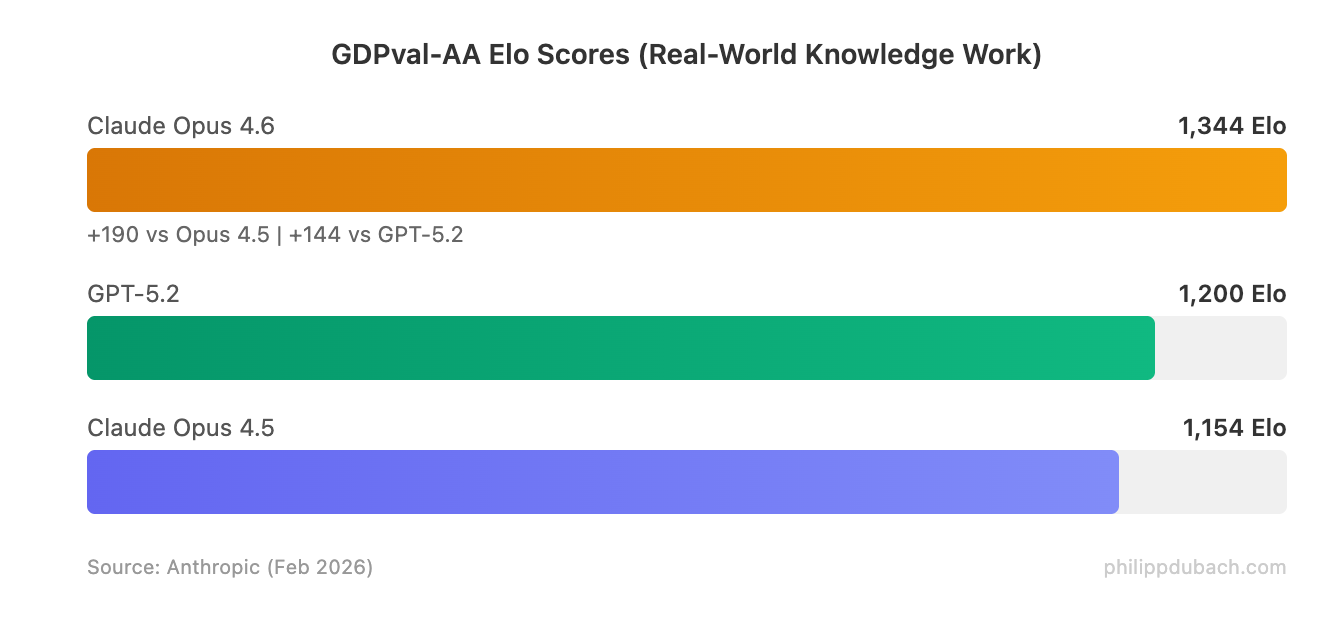
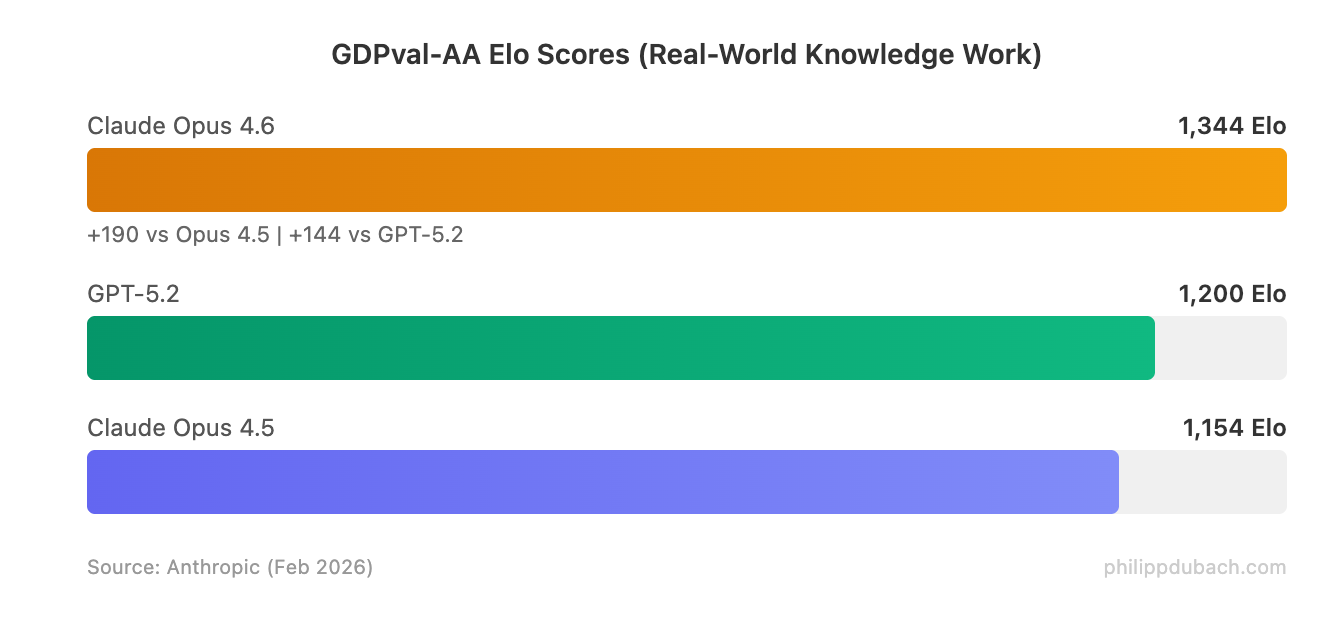
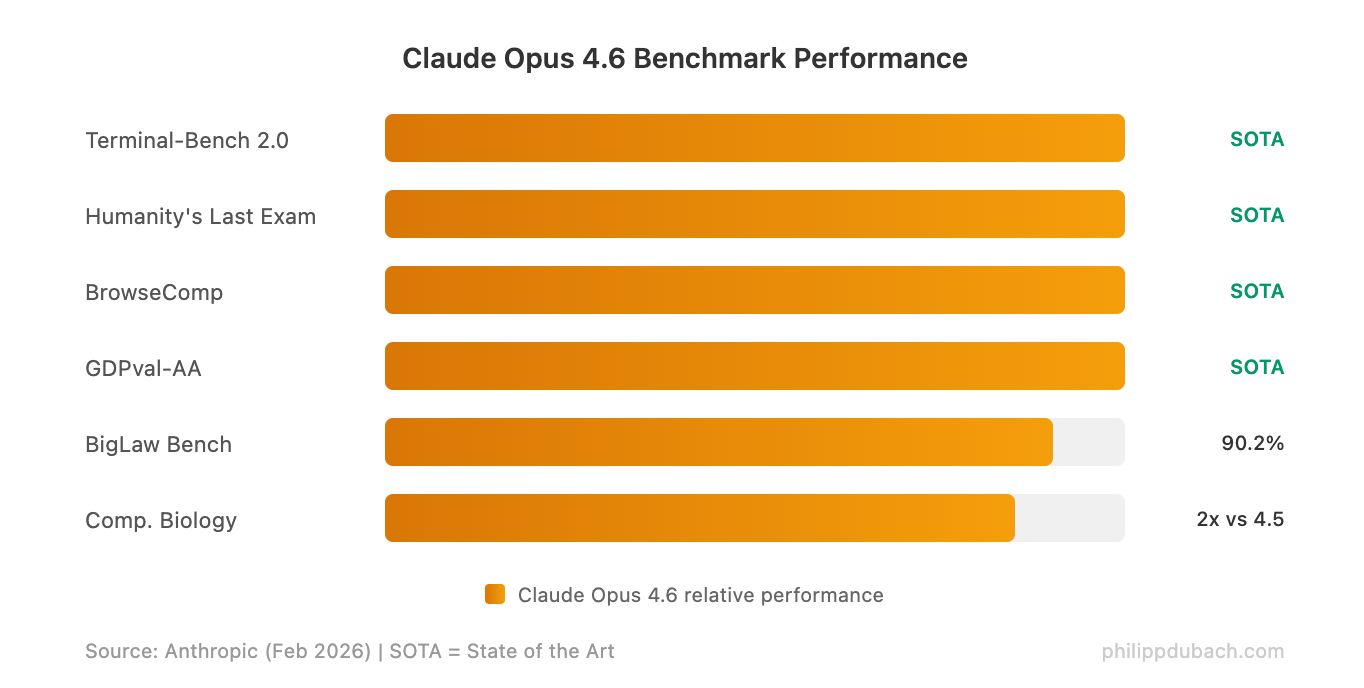
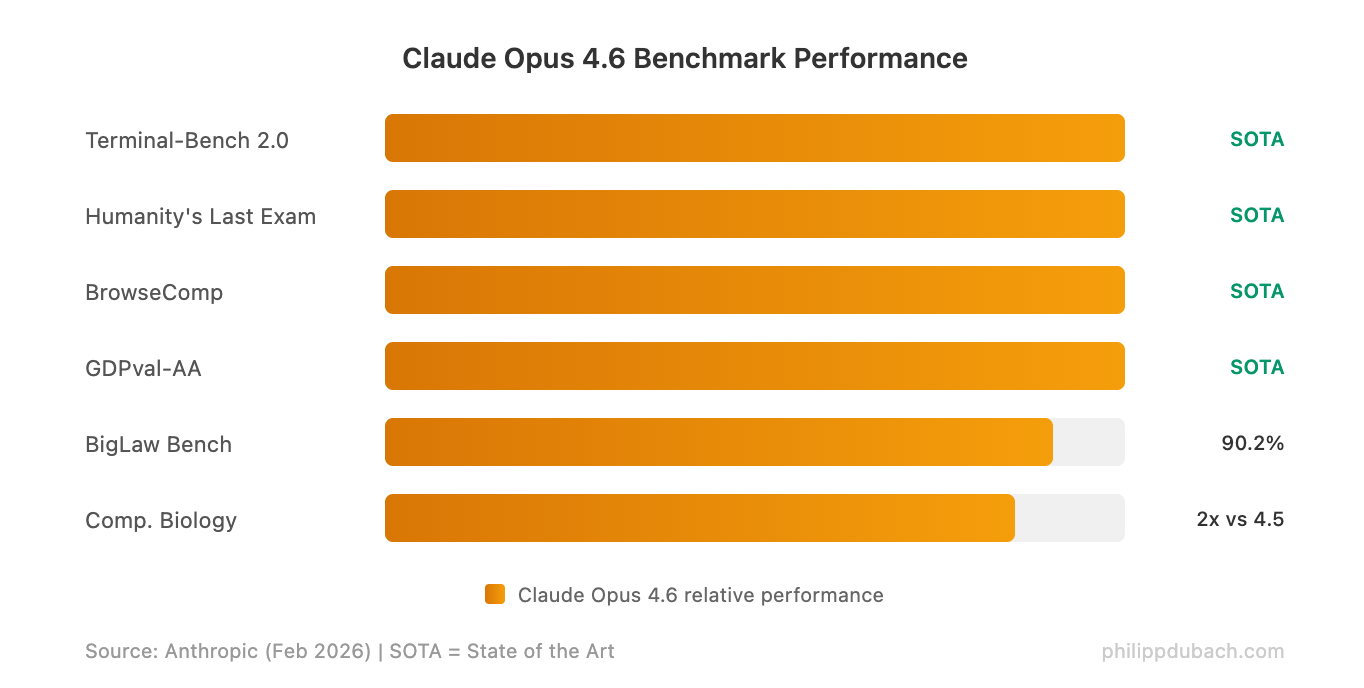
The benchmark numbers are strong across the board. Opus 4.6 hits state-of-the-art on Terminal-Bench 2.0 (65.4% for agentic coding in the terminal), Humanity’s Last Exam (complex multidisciplinary reasoning), and BrowseComp (agentic web search). It beats GPT-5.2 by roughly 144 Elo points on GDPval-AA, the benchmark that measures real-world knowledge work across 44 professional occupations.
 The standout is ARC-AGI-2, which tests abstract reasoning on problems easy for humans but hard for AI. Opus 4.6 scores 68.8%, a dramatic leap from Opus 4.5’s 37.6%. For comparison, GPT-5.2 scores 54.2% and Gemini 3 Pro hits 45.1%. That gap matters because ARC-AGI-2 resists memorization — it measures whether models can actually generalize.
The standout is ARC-AGI-2, which tests abstract reasoning on problems easy for humans but hard for AI. Opus 4.6 scores 68.8%, a dramatic leap from Opus 4.5’s 37.6%. For comparison, GPT-5.2 scores 54.2% and Gemini 3 Pro hits 45.1%. That gap matters because ARC-AGI-2 resists memorization — it measures whether models can actually generalize.
On coding-specific evaluations, Terminal Bench 2.0 rises to 65.4% (from 59.8% for Opus 4.5), and OSWorld for agentic computer use jumps from 66.3% to 72.7%, putting Opus ahead of both GPT-5.2 and Gemini 3 Pro on those particular tests. SWE-bench Verified shows a small regression — worth watching, though the model excels on the benchmarks that better reflect real production work.
What Can You Do With a 1 Million Token Context Window?
The 1M context window paired with the new context compaction feature is the most practically interesting upgrade. To put it in perspective: 1M tokens covers roughly 750 novels, an entire enterprise codebase of several thousand files, or a full legal discovery set — processed in a single prompt.
Compaction automatically summarizes older context when approaching limits, which means agents can theoretically run indefinitely without hitting the wall that’s plagued long-running AI tasks. Combined with the model’s improved ability to catch its own mistakes through better code review and debugging, you’re looking at agents that can actually finish what they start.
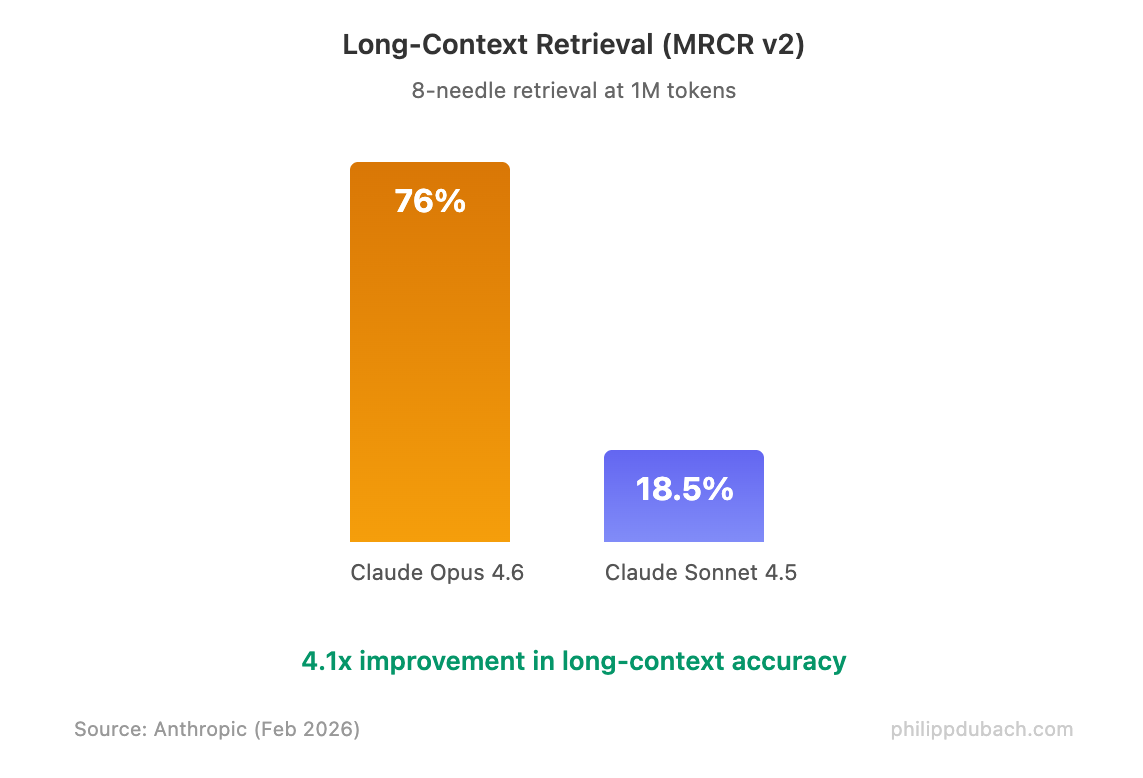
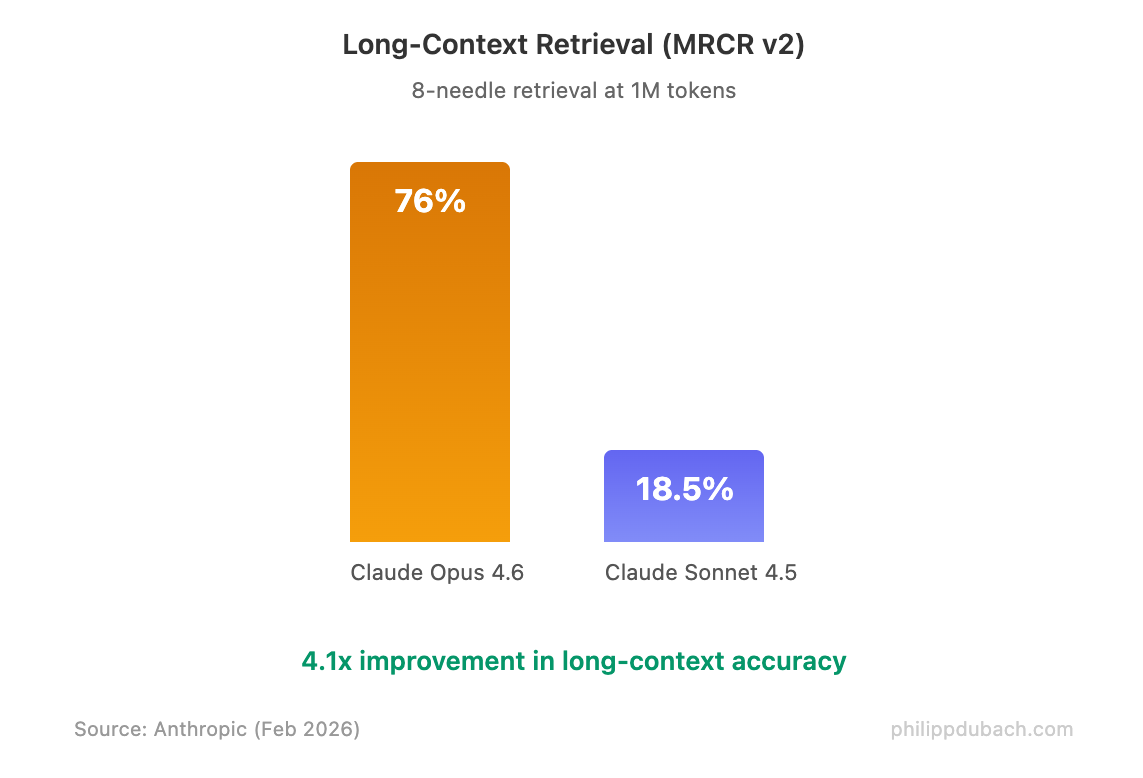
The long-context retrieval jump tells the story. On MRCR v2, which tests whether a model can find and reason over specific facts buried in massive prompts, Opus 4.6 scores 76% compared to Sonnet 4.5’s 18.5%. That’s not an incremental improvement — it’s a different capability class.
 That said, bigger context doesn’t automatically mean better. Research from Factory.ai and others shows attention degrades across very long sequences, and prefill latency at 1M tokens can exceed two minutes before you get your first output token. The premium pricing tier for prompts exceeding 200K tokens ($10/$37.50) reflects this cost — Anthropic isn’t subsidizing power users anymore. The real question for enterprise deployments is whether stuffing your entire codebase into context beats a well-designed RAG pipeline. The answer, as usual, depends on the use case.
That said, bigger context doesn’t automatically mean better. Research from Factory.ai and others shows attention degrades across very long sequences, and prefill latency at 1M tokens can exceed two minutes before you get your first output token. The premium pricing tier for prompts exceeding 200K tokens ($10/$37.50) reflects this cost — Anthropic isn’t subsidizing power users anymore. The real question for enterprise deployments is whether stuffing your entire codebase into context beats a well-designed RAG pipeline. The answer, as usual, depends on the use case.
Agentic AI Coding: Agent Teams and Claude Code Updates
The headline numbers impress, but the real story is the agentic focus. Anthropic isn’t just making Claude smarter. They’re making it more useful for the actual work people want AI to do: sustained, multi-step tasks in large codebases.
New API features reinforce this direction: adaptive thinking lets the model decide when to reason deeper based on contextual cues, effort controls give developers fine-grained tradeoffs between intelligence, speed, and cost (low/medium/high/max), and context compaction keeps long-running agents within limits without manual intervention.
Claude Code gets the headline feature: Agent Teams that work in parallel. Multiple subagents can coordinate autonomously on read-heavy work like codebase reviews, with each agent handling a different branch via git worktrees before merging back. This ships as a research preview, but it’s clearly aimed at the production workflows where agentic coding tools like Cursor, GitHub Copilot, and OpenAI’s Codex are competing hard. The timing isn’t accidental — Apple just announced Xcode 26.3 with native support for Claude Agent and OpenAI’s Codex via MCP (Model Context Protocol), making agentic coding a standard part of the developer toolchain rather than an experiment.
Enterprise Deployment: Why GDPval-AA Matters
The GDPval-AA benchmark deserves special attention because it measures performance on real-world knowledge work — not toy problems or academic puzzles. Beating GPT-5.2 by 144 Elo points (and Opus 4.5 by 190) suggests meaningful improvements in the tasks that matter for enterprise AI adoption: financial analysis, legal reasoning, and multi-step professional workflows.
The product expansions signal where Anthropic sees the market going. Claude in Excel now handles long-running tasks and unstructured data. Claude in PowerPoint reads layouts and slide masters for brand consistency. These aren’t research demos — they’re enterprise-ready integrations designed for knowledge workers who need AI that fits into existing toolchains.
For teams evaluating which frontier model to standardize on, the picture is nuanced. Claude Opus 4.6 leads on agentic coding and enterprise knowledge work. GPT-5.2 still holds advantages in abstract reasoning (ARC-AGI-2, though the gap narrowed significantly) and math. Gemini 3 Pro offers the best cost efficiency and multimodal processing with its own 1M context window. The multi-model workflow trend is real — the smartest enterprise teams aren’t picking one model; they’re routing tasks to whichever model handles them best.
Safety Profile and the Zero-Day Question
One detail worth noting: the safety profile. Anthropic claims Opus 4.6 is “just as well-aligned as Opus 4.5, which was the most-aligned frontier model to date.” Given the enhanced cybersecurity capabilities — Opus 4.6 independently discovered over 500 previously unknown zero-day vulnerabilities in open-source code during Anthropic’s pre-release testing — they developed six new detection probes specifically for this release.
Whether that’s reassuring or concerning depends on your priors about AI capabilities research. The vulnerabilities ranged from system-crashing bugs to memory corruption flaws in widely-used tools like GhostScript and OpenSC. As Logan Graham, head of Anthropic’s frontier red team, put it: it’s a race between defenders and attackers, and Anthropic wants defenders to have the tools first.
What This Means for the Competitive Landscape
The competitive landscape just got more interesting. GPT-5.2 and Gemini 3 Pro now have a new benchmark to chase, and Anthropic has clearly staked its claim on agentic coding as the primary battleground. With pricing unchanged at $5/$25 per million tokens — significantly more expensive than GPT-5.2 at $2/$10 but competitive for the performance tier — the value proposition comes down to whether the agentic improvements translate to fewer retries, less hand-holding, and faster task completion in your specific workflow.
For developers, the move is straightforward: swap in claude-opus-4-6 via the API and test it on your hardest tasks. For enterprise decision makers, the GDPval-AA results and Agent Teams feature are worth a serious evaluation cycle. The model is available now on claude.ai, the API, and all major cloud platforms (AWS Bedrock, Azure Foundry, GCP Vertex AI).