I built a tennis broadcast pipeline this spring and ended up running F3ED, the NeurIPS 2024 shot detector, on a couple of ATP Challenger matches. F3ED is a good model. It also kept labeling clear aces as “unforced errors”, which is what this post is about. Code: github.com/philippdubach/tennis-vision.
F3ED (NeurIPS 2024) detects shots well. The catch is the outcome head, which has 4 classes: in, winner, forced-err, unforced-err. There’s no class for ace, double_fault, or first_serve_fault. Those events aren’t shot properties; they’re score-grammar, and they need state from outside the shot itself.
I audited 11 single-shot serve rallies F3ED labeled unforced-err. 7 are first-serve-faults. 1 is an ace. Only 3 are genuine unforced-errors. 73% mislabeled by tennis’s own definition.
The fix is a 30-line reconciler that reads the scoreboard. OCR isn’t novel here. What I haven’t seen anyone do is plug it back into runtime label correction, which is what makes the difference. N=44 rallies across two matches; this is a hypothesis, not a finding. The structural argument doesn’t depend on N.
The current pipeline
Two phases, with a serializable artifact between them:
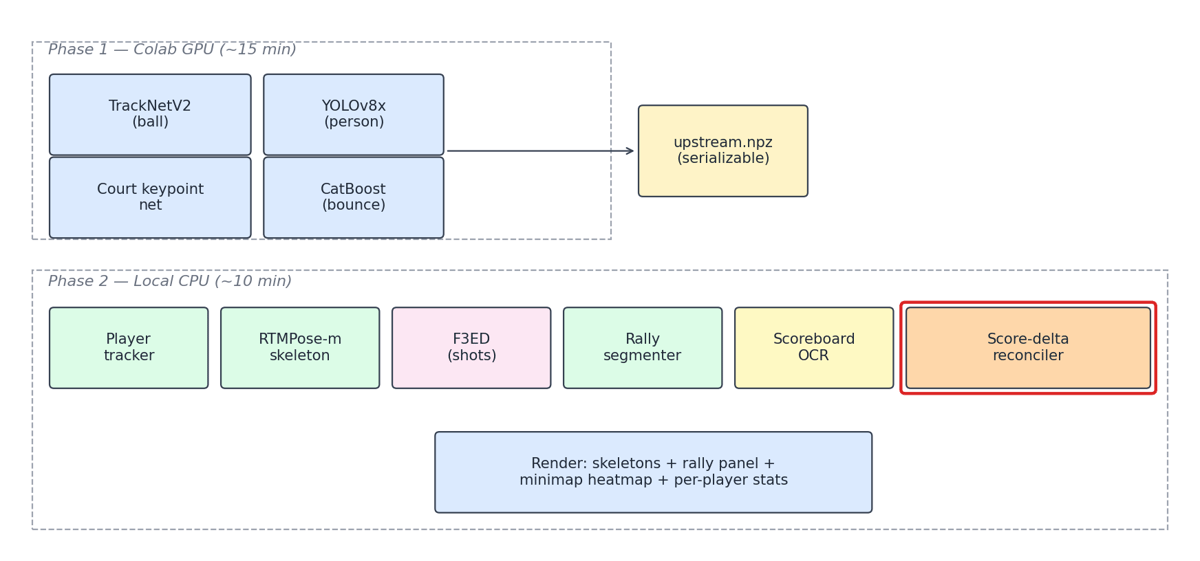
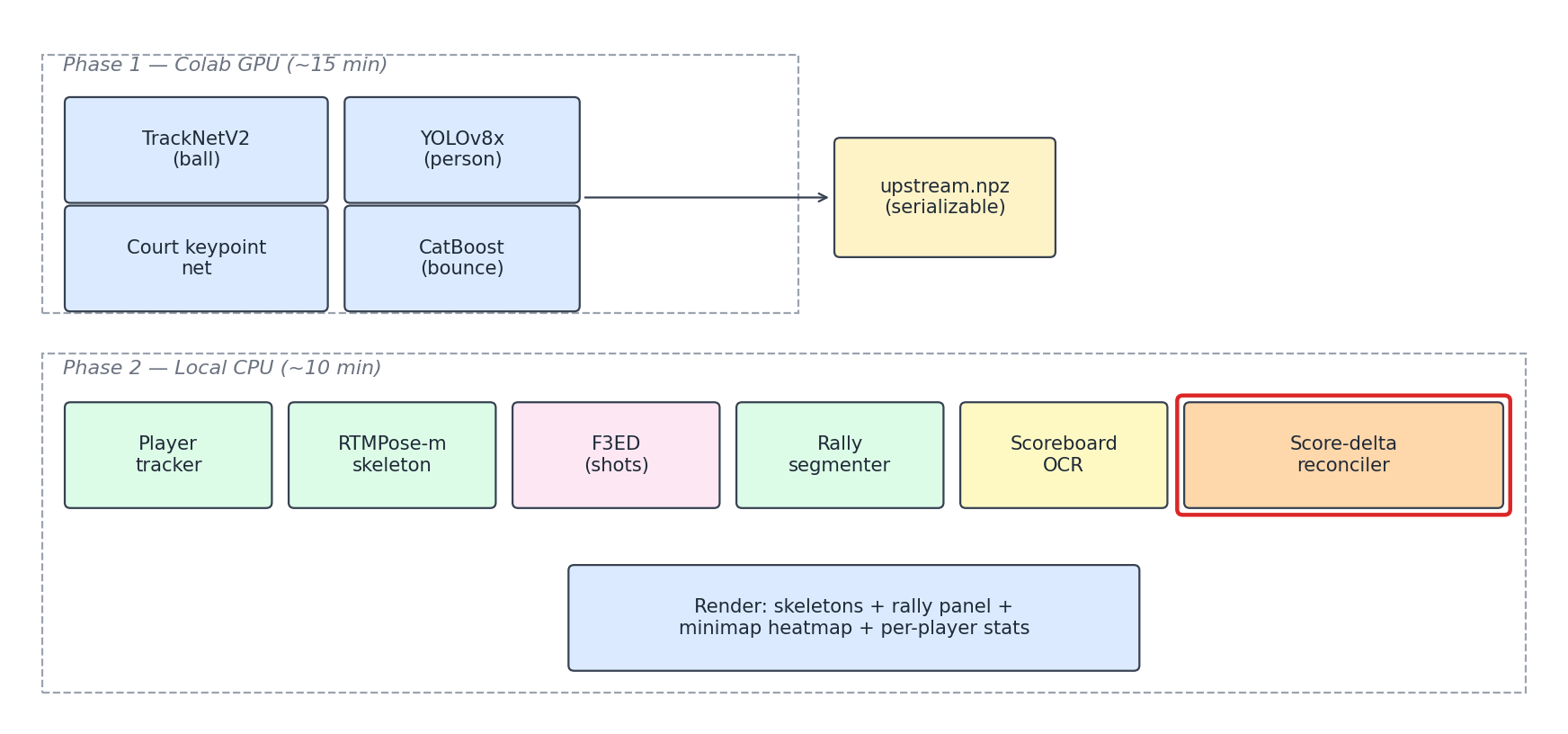
upstream.npz is a 5-field dataclass (ball_track, homography_matrices, kps_court, persons_top/bottom, bounces). It’s the contract between the GPU-bound detection layer and everything else. You re-run Phase 2 in seconds and don’t pay the GPU bill again until Phase 1 inputs change. This was a boring early decision that quietly carried the project. Every iteration runs in ~10 minutes instead of needing a fresh Colab session.
The score-delta reconciler sits at the end of Phase 2. It sees F3ED’s per-shot taxonomy and the OCR-derived score states. When they disagree, it overrides the outcome label.
Quality on TenniSet V006 (28 ground-truth points across 20 minutes, with ±12-frame tolerance):
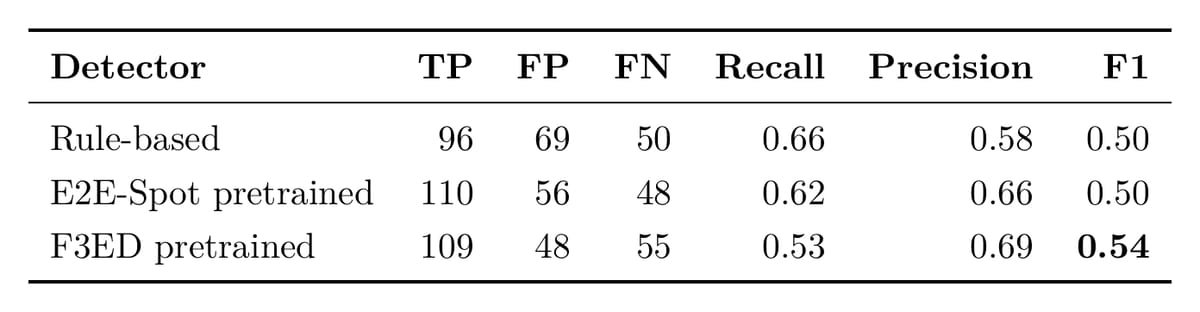
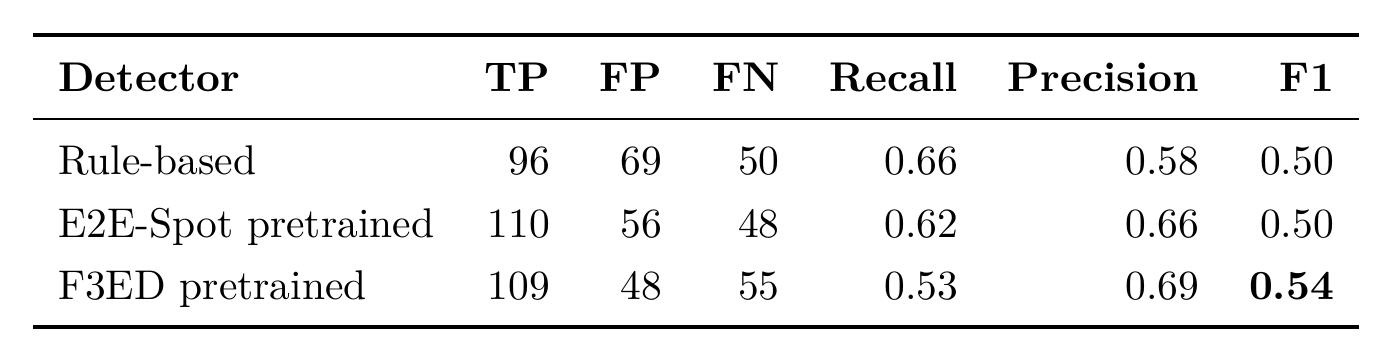
F3ED has the highest F1, with fewer false positives at comparable recall. I’m not arguing it’s broken. I’m arguing about a specific thing it can’t do alone.
Note: numbers above are from the V006 baseline run on commit
0babb71(2026-04-23). Bounce-dedup and reconciler work since then shift F1 marginally upward; full re-eval pending a Phase-1 v8x rerun on V006.
The audit
Tennis scoring is a finite-state machine. A point ends in exactly one of:
ace: server’s first or second serve, receiver doesn’t returndouble_fault: both serves missfirst_serve_fault: first serve misses; second serve still to come- multi-shot rally →
winner/forced-err/unforced-err
F3ED can only emit the bottom row. The first three depend on what happens between shots, or on what doesn’t happen at all, and the model doesn’t see between-shot stuff. It also has no class to put the answer in if it did: ace, double_fault, and first_serve_fault are not in F3ED’s published label set. The closest available emission for any of them is serve + unforced-err. The model can’t learn to distinguish them even if the training data did, because there’s nowhere to put the answer.
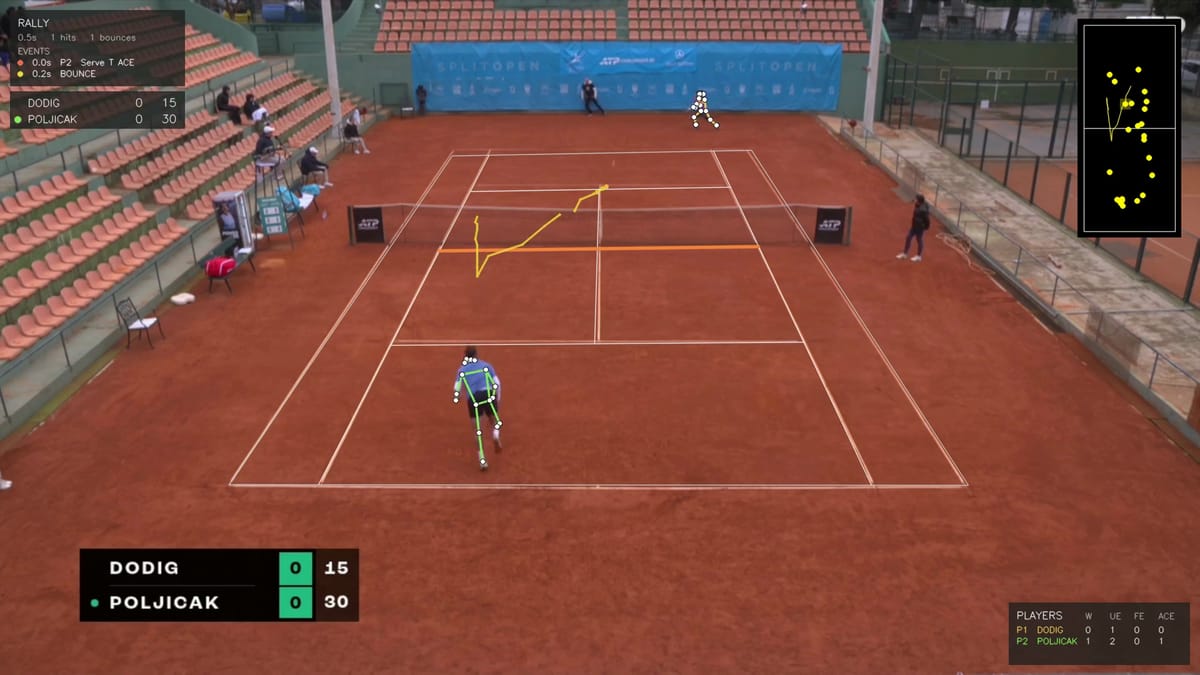
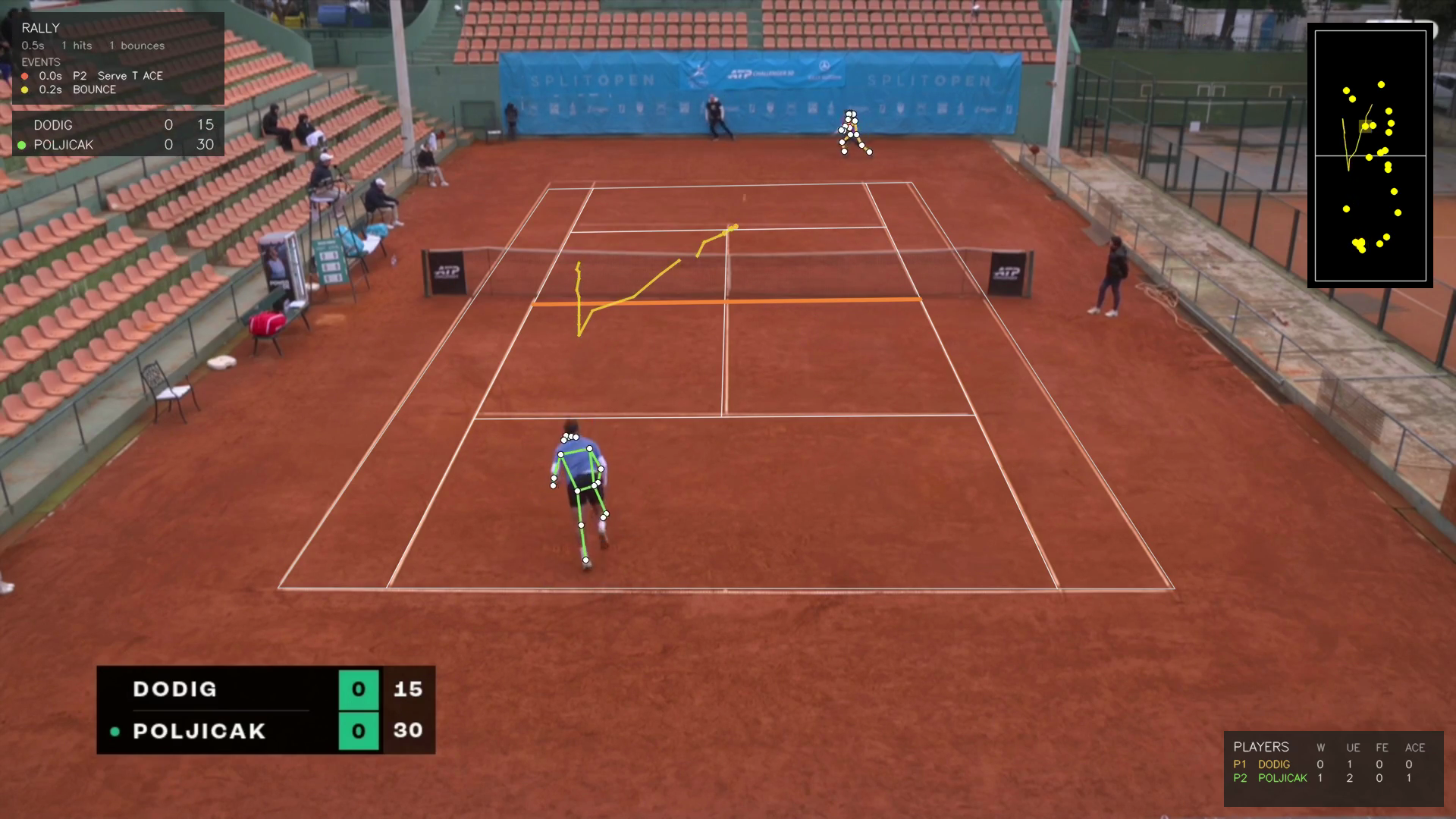
Here’s what tipped me off. set1 R4, t=107s:
| |
Server scored, receiver didn’t move, F3ED labeled the serve “unforced error”. You can’t hit an unforced error and win the point. It was an ace, and F3ED doesn’t have an “ace” button to press, so it picked the closest available label.
The reconciler is short. For each single-shot serve rally, read the scoreboard before and after:
| |
That’s the whole reconciler: 23 lines, microseconds per rally. The OCR sampling pass that produces the before / after states runs once during Phase 2 (~1 Hz over the broadcast); the reconciler itself is a constant-time lookup against the resulting state timeline.
Running it across set1 + match2 (44 rallies, 11 single-shot serve rallies) shows the structure F3ED missed:
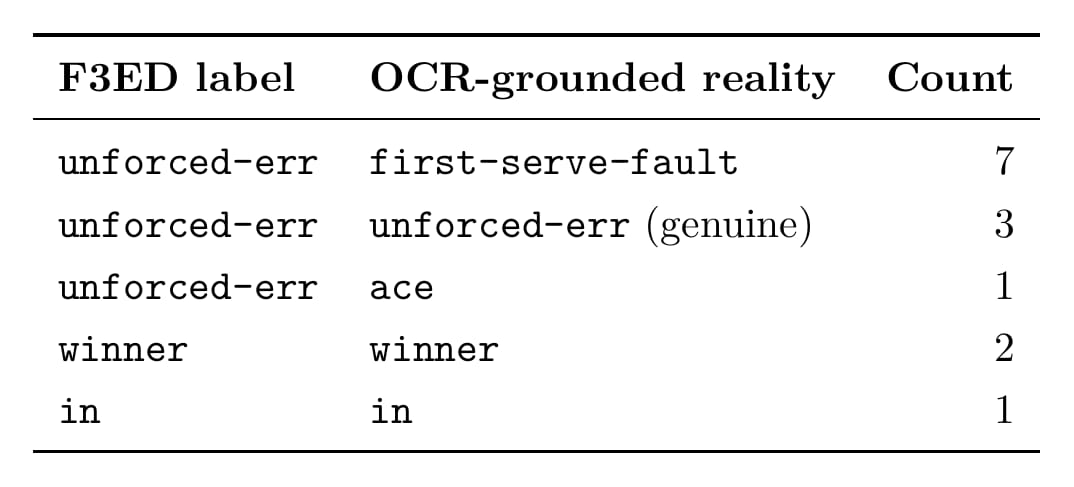
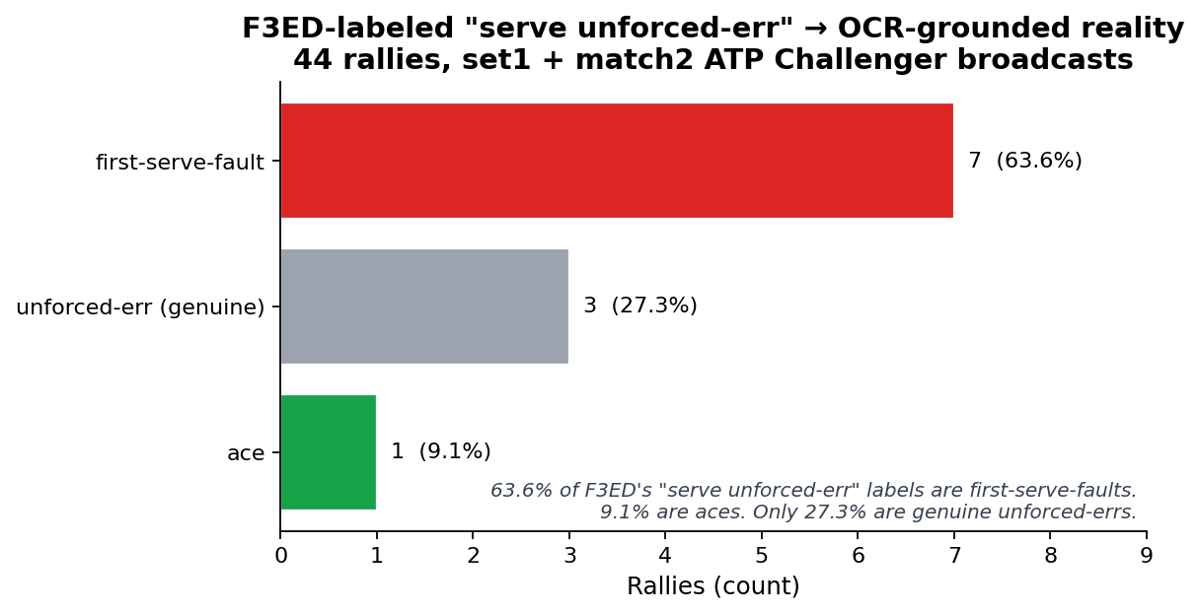
8 of 11 unforced-err serves (73%) are something else by tennis’s actual rules. All 8 got the right label after reconciliation. Whether 73% holds up on a larger sample is a real question; the audit framework would answer it cheaply on more clips. The remaining error budget is OCR layout failures (next section) and ambiguous score deltas in multi-shot rallies, where neither F3ED nor OCR alone tells winner from forced-err.
The point here isn’t that F3ED is wrong. The model emits the labels it has classes for, which is what models do. The point is that shot detection and outcome classification look like the same problem and aren’t, and on broadcast tennis the cheapest outcome ground truth is text the broadcaster has already burned into the corner of every frame.
Does the OCR actually work?
Worth asking. The whole reconciler depends on the scoreboard reader being right. Honest answer: it depends heavily on whether the layout config is tuned. When it is, OCR is reliable. When it isn’t, individual fields collapse.
The pipeline is EasyOCR cropping a per-layout ROI (split_open_1080p, split_open_720p, bloomfield_720p), then a tennis-grammar decoder that rejects illegal transitions (40-30 → 0-0 without a game break, AD-15, and so on) and majority-votes within a sample window.
Field-parse rates on the two clips in this audit, sampled at ~1 Hz:


set1 is essentially perfect. match2’s bot_games parse drops below half because the ROI for split_open_720p is mistuned and crops too tight on the digit. Annoying, but the grammar decoder rescues enough frames to emit 28 valid score states across 1002 samples, which is plenty. The reconciler degrades gracefully: rallies without a clean before/after pair fall back to F3ED’s raw outcome rather than crashing.
The fix for match2 is layout cleanup, not architecture. None of these components are novel. TennisExpert (Liu et al. 2026, the paper that kicked off this whole project for me) and the TenniSet eval framework (Faulkner & Dick, DICTA 2017) both use OCR + grammar at the labeling stage. What I haven’t seen anyone do is plug the same signal back into runtime label correction.
Putting it in the render
After reconciling, the corrected outcome flows back onto the last shot of the rally and surfaces in the rolling event-timeline panel. Here’s a single point rendered end-to-end with all overlays live:
Same set1 R4 ace, mid-frame: Top-left RALLY panel reads 0.0s P2 Serve T ACE. The ACE suffix replaced F3ED’s UE. The scoreboard echo (bottom-left) mirrors what triggered the correction (Poljicak just picked up 15), and the per-player stats panel (bottom-right) ticks his ace counter by one. The model’s wrong answer gets quietly corrected because a different signal contradicted it. That’s the whole post in one frame.
The same panel surfaces F3ED’s other labels in real time: direction (T for down-the-T serves, CC/DL/DM/II/IO for groundstrokes) and shot type when not a basic groundstroke (Slice, Volley, Drop, Lob).
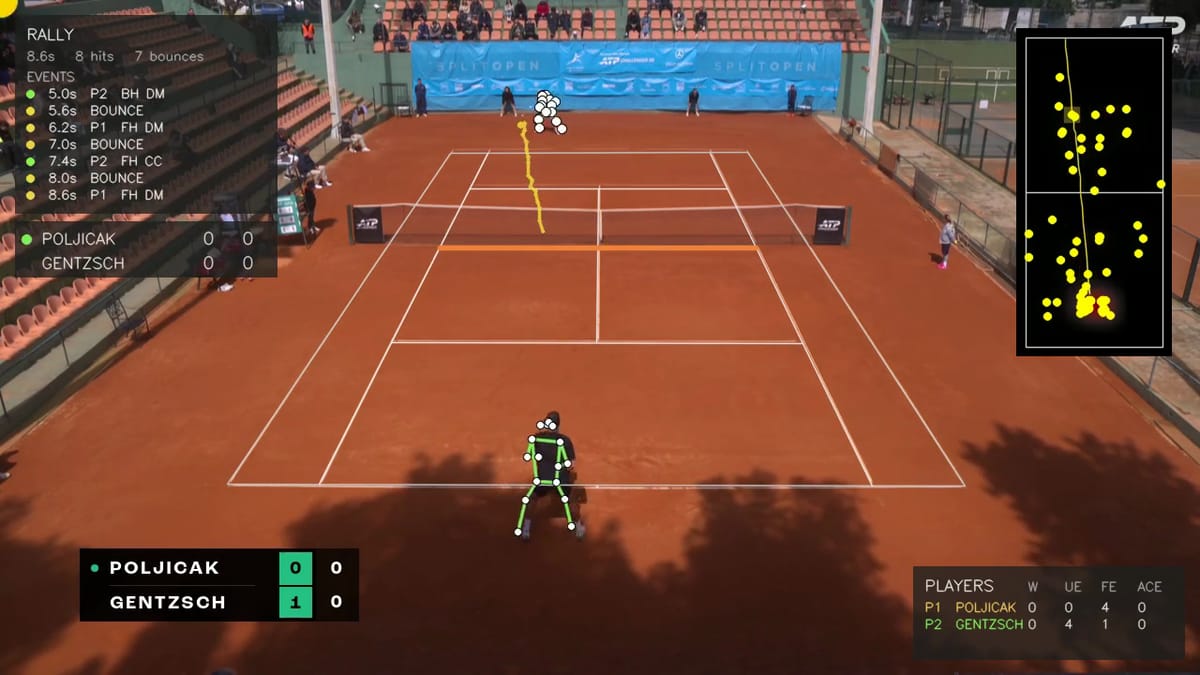
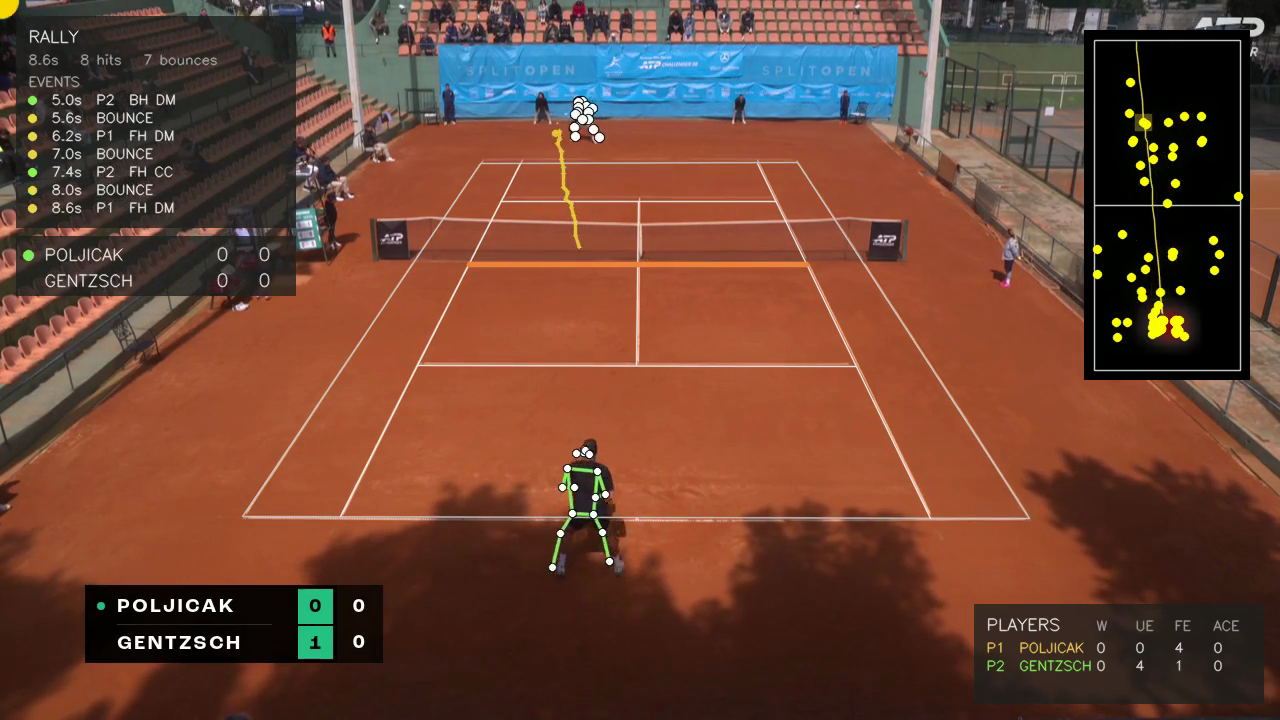
That panel is the F3ED 29-class taxonomy made human-readable, in real time. The reconciler doesn’t touch direction or technique. Those are pure shot properties, exactly the regime F3ED is designed for. It only fires on the score-grammar events the model can’t see.
A clean direction histogram comes for free as a side effect. 97 groundstrokes from match2:
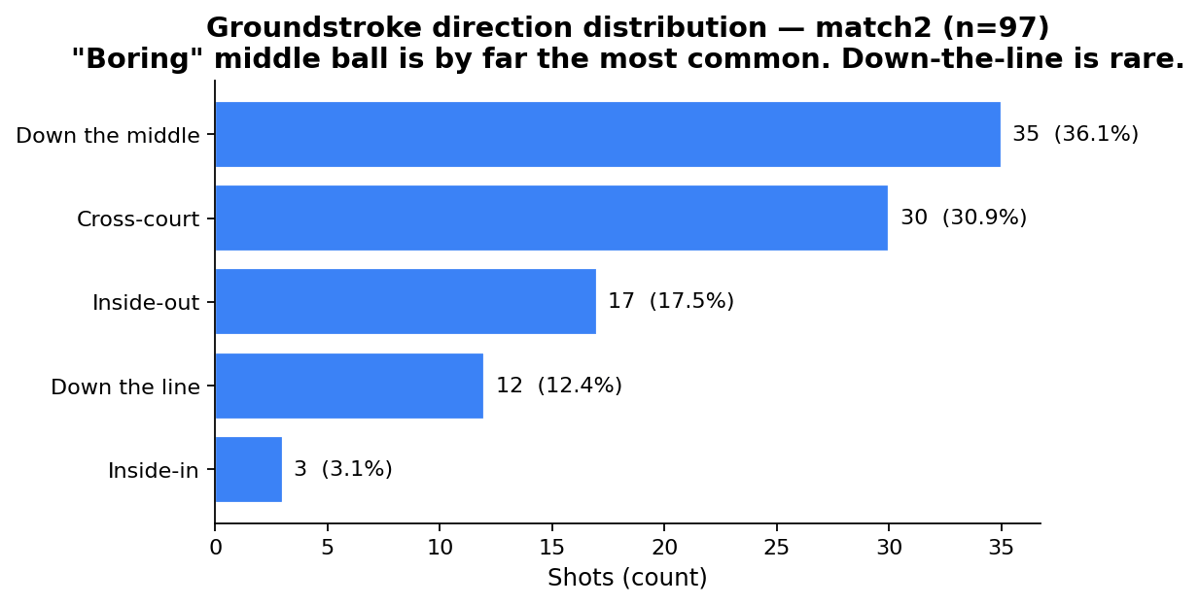
36% down the middle, 31% cross-court, 17% inside-out, 12% down-the-line, 3% inside-in. The kind of stat broadcasters quote without showing where it came from. Here it’s a one-liner over shots.json.
Things that didn’t pay off
Two ideas I tried that I expected to be wins. Neither was.
YOLOv8x doesn’t help at 720p
Phase-1 person detector was YOLOv8m. Swapping in v8x looked like a free improvement: COCO AP@small bumps about 5 pp, and the camera-far (“top”) player on broadcast tennis is the smallest object in the frame, so that’s exactly where the gain should land.
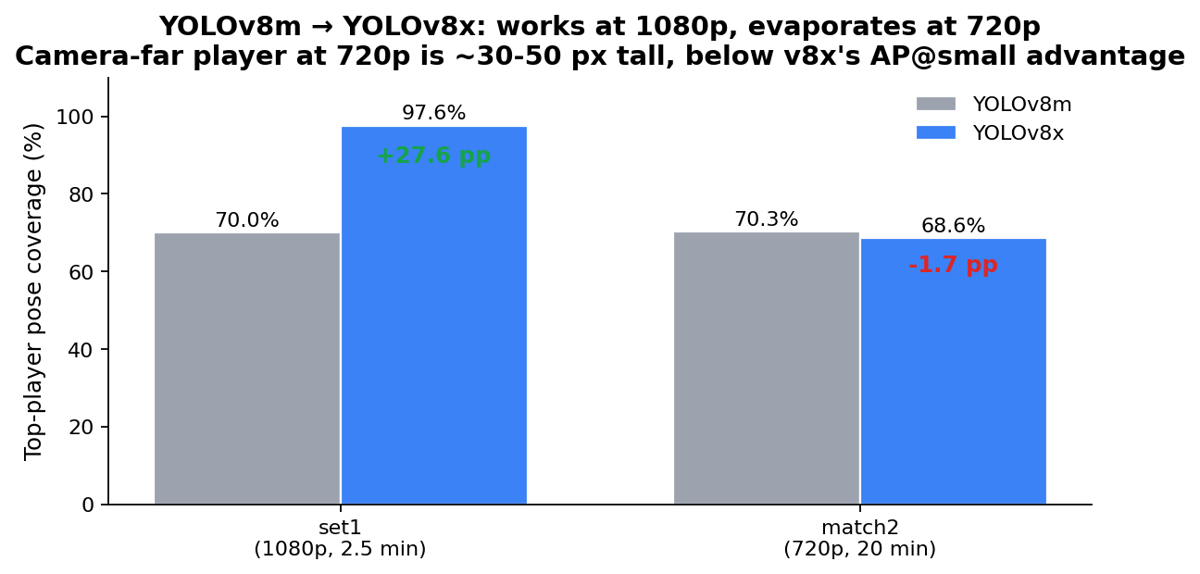
set1 (1080p): top-player pose coverage 70.0% → 97.6%. match2 (720p): 70.3% → 68.6%, within noise. Two clips isn’t a study, but the mechanism is plausible: at 1080p the camera-far player is ~60-100 px tall, the regime where v8x’s AP@small advantage fires. At 720p the same player is ~30-50 px, below the COCO scale buckets where -x outperforms -m. The detector can’t recover what isn’t in the input. If you’re scraping ATP Challenger feeds, fight for 1080p sources. Everything downstream compounds on what the detector gives you.
CatBoost over-fires bounces
The bounce detector emitted 378 bounces on a 20-min match2 clip with 84 shots, 4.5× the realistic ratio. Most of the noise is the detector lighting up on the same physical bounce across consecutive frames, plus inter-rally footage where the ball is in a player’s hand or in a replay close-up.
Two cheap filters cut 21-27% of false bounces:
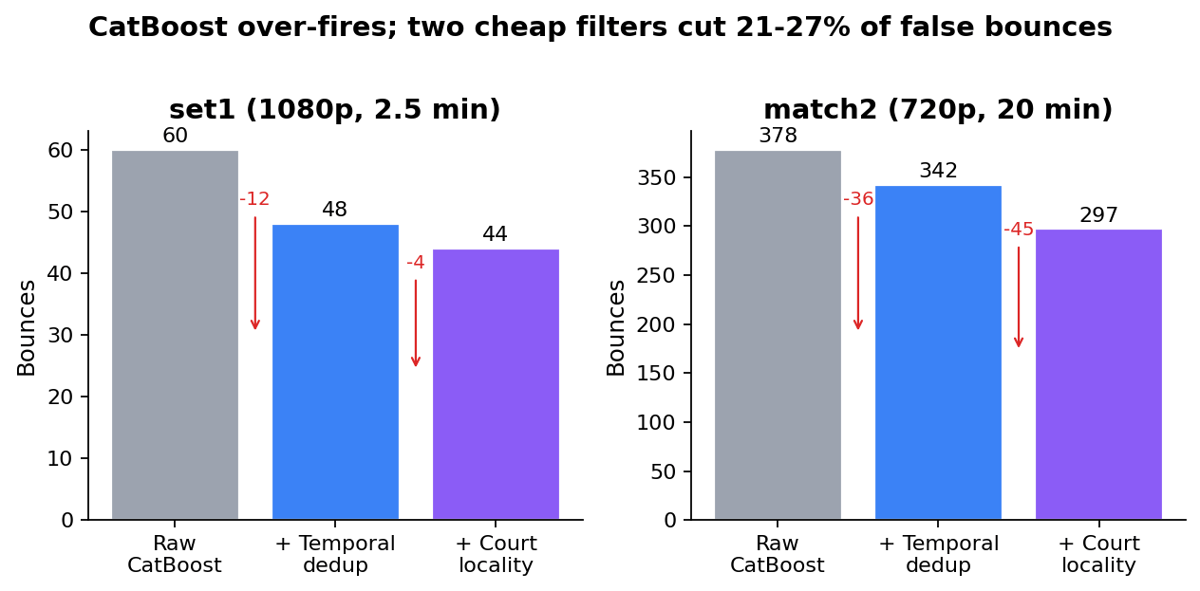
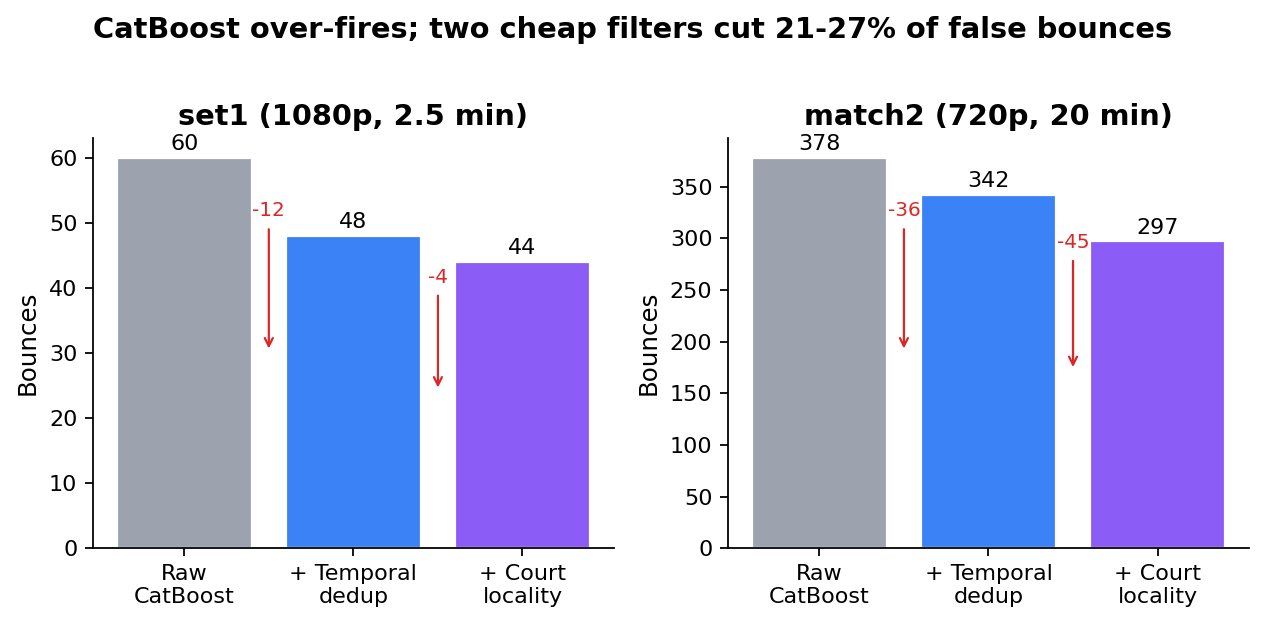
The first is a temporal dedup with ~400 ms minimum separation between bounces, fps-aware. It collapses CatBoost firing on three consecutive frames for one physical contact and drops 9-12%.
The second is a court-locality filter: project the ball pixel through the homography to canvas coordinates, drop if it falls outside the court polygon plus a 200 px buffer. This kills inter-rally noise where the ball is being held or replayed, dropping another 12-15%.
Real bounces don’t fire 200 ms apart and don’t land 3 m past the doubles alley. Neither filter is novel; both are roughly ten lines of code. If you’re using a CatBoost-style bounce detector you probably want both anyway.
What’s open
44 rallies isn’t enough to nail the percentage, just to expose the structure. Running the audit across 10+ matches is the obvious next step. It would also surface match-to-match variance in F3ED’s failure modes. Does it mislabel aces more often on hard courts than clay? I have no idea, and I’d like to know.
The reconciler currently only handles single-shot serve rallies. When both players hit clean balls and the point ends, the score delta is the same whether the winner came from a winner or a forced-err. Neither F3ED nor OCR alone disambiguates. A trajectory-aware classifier on the last two shots would close that gap. Haven’t tried it.
The longer-term move is closed-loop F3ED retraining: use the OCR-corrected labels as supervision for a small classifier head whose input is (F3ED 4-class outcome, OCR delta, single-shot flag) and whose output is the extended set {in, winner, forced-err, unforced-err, ace, double_fault, first_serve_fault, unreturnable}. About 5 minutes of training data per match. 10+ matches gets a usable head. The interesting move there is putting the OCR signal into training rather than just inference.