# Inside PRAGMA: Revolut's Foundation Model for Banking
**Author:** Philipp D. Dubach | **Published:** April 26, 2026
**Categories:** AI
**Keywords:** PRAGMA, Revolut foundation model, banking foundation model, nuFormer Nubank, transformer banking transactions, self-supervised learning transactions
## Key Takeaways
- Revolut's PRAGMA scales from 10M to 1B parameters, pretrained on 24B events from 26M users across 111 countries.
- PRAGMA delivers +130% PR-AUC on credit scoring and +163% AUUC on uplift via LoRA fine-tuning of a shared backbone.
- The model fails badly on anti-money-laundering (-47% F0.5) because it processes records in isolation rather than across users.
- Nubank's nuFormer reaches the same conclusion via a different architecture, suggesting the field is converging.
---
This month, Revolut Research and NVIDIA published [PRAGMA](https://arxiv.org/abs/2604.08649): an encoder-only transformer trained on 26 million user histories spanning 24 billion events and 207 billion tokens across 111 countries. To my knowledge it is the largest encoder backbone for consumer banking event data anyone has put on arXiv. Nine months earlier, Nubank had published [nuFormer](https://arxiv.org/abs/2507.23267), a similar premise with the opposite architecture. Can you train a transformer on raw transaction ledgers and replace the gradient-boosted-tree models running production credit, fraud, and recommendation pipelines.
Banking has spent the last decade lagging the rest of tech on representation learning. Production models still run on hand-crafted tabular features. Every team working on this knows it's is suboptimal. Almost no team has the data, the GPUs, or the political budget to fix it. PRAGMA is what a banking foundation model looks like at the high end of the market.
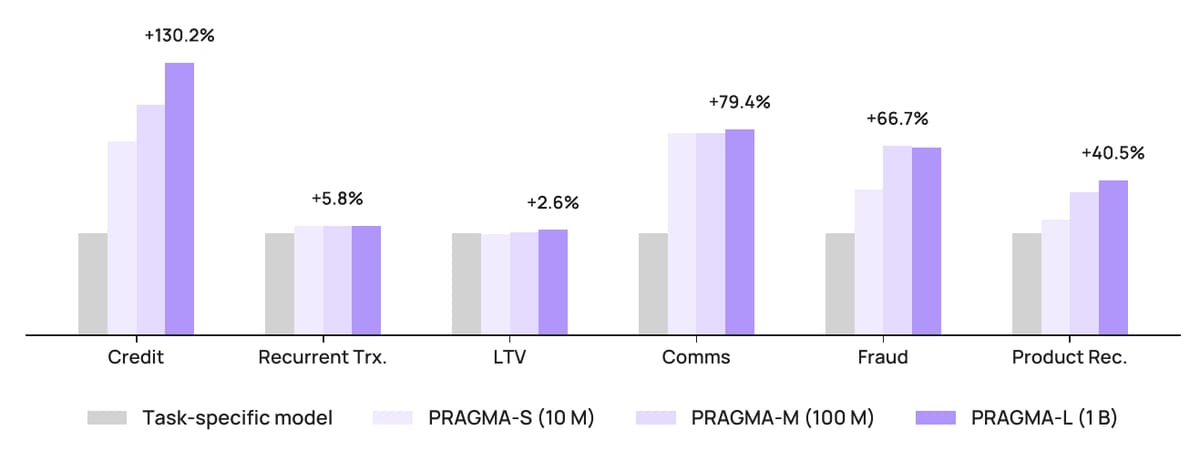
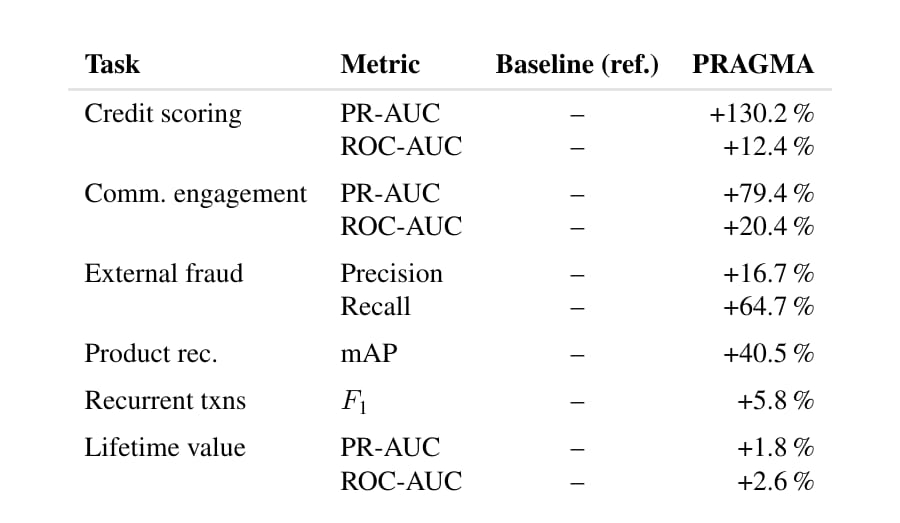
The chart above is from the PRAGMA paper and it reads like a marketing slide. PR-AUC up **130.2%** on credit scoring. AUUC up **163.7%** on a communication uplift task. mAP up **40.5%** on product recommendation. These are relative numbers against task-specific baselines and the absolute scores are commercially redacted, so calibrate accordingly. But Revolut publishing them under their own name, with author affiliations, is the meaningful signal here. Internal foundation models have moved from trade secret to competitive disclosure.
## What Revolut built
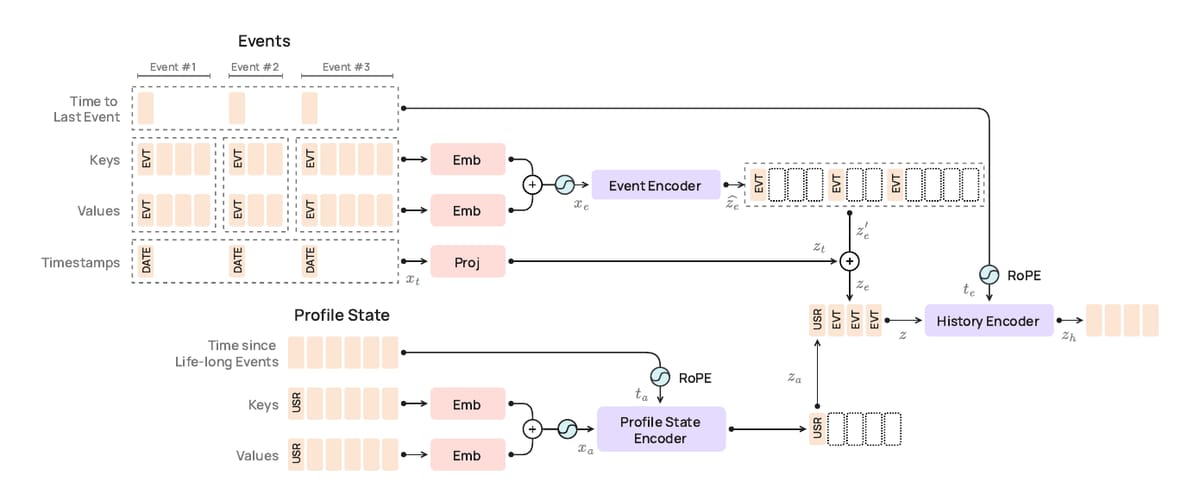
PRAGMA is a BERT-style encoder, not a GPT. The choice matters. Revolut's downstream targets are discriminative (default within 12 months, fraud, churn, product adoption), which is exactly what bidirectional masked modelling is good at. The model family scales from 10M to 100M to 1B parameters across three encoder branches: a profile-state encoder for static attributes, a per-event encoder, and a history encoder that fuses them.
The architectural decision that strikes me as most important is the input representation. Naive text serialization of a transaction record into JSON blows up sequence length: every key name, every delimiter, every digit becomes multiple BPE subword tokens. Worse, splitting "14.99" into "14" "." "99" destroys the magnitude information that any credit model needs. Revolut's answer is to tokenise each field as a triple of semantic key, typed value, and temporal coordinate. Numerical values map to learned percentile buckets. Categorical values map to single tokens. Text gets BPE. Timestamps get encoded twice, once as compressed log-seconds since the previous event and once as fixed-period sinusoids over hour-of-day, day-of-week, and day-of-month.
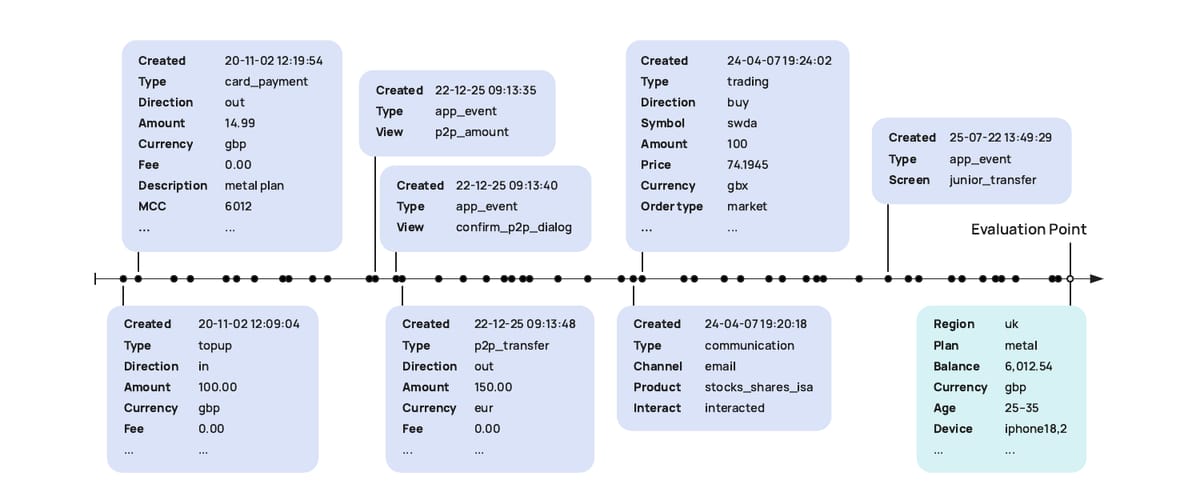
The figure above is what a single user looks like to PRAGMA: a stream of structured events leading up to an evaluation point at which the model is asked to predict something. Around 60 keys. Around 28,000 value tokens.
Pre-training is masked language modelling, but with three masking sources blended together: 15% standard token masking, 10% whole-event masking, and 10% semantic-type masking. The whole-event variant is interesting for banking. It teaches the model that when you cannot see the amount of a card payment but you can see the merchant, the time, and the surrounding behavioural pattern, the amount is often inferable. That is exactly the inductive bias you want in a credit or fraud model.
## The numbers
(1) The LoRA versus train-from-scratch comparison. Revolut shows that fine-tuning a pre-trained backbone with LoRA, updating roughly 2-4% of parameters, consistently matches or beats training a fresh task-specific model on the same downstream data. This is the result that justifies the entire infrastructure investment. If pre-training did not transfer, you would not bother. Communication engagement gains **18.6%** PR-AUC from LoRA over scratch. Credit scoring gains **13%**. Product recommendation gains **10.3%** mAP. That is the business case.
(2) The profile-state ablation. Removing the dedicated profile-state branch tells you which tasks are driven by static user characteristics versus event sequences. Credit scoring loses **31.8%** PR-AUC without profile state, because account tenure and onboarding signals matter for identifying minority-class defaulters. Communication engagement actually gains 3% in PR-AUC without profile state, because re-engagement is a story about pre-drop-off behaviour, not about who the user is. The two-branch design keeps the static features when they help and ignores them when they do not.
(3) The failure. PRAGMA loses **47.1%** on F-0.5 against the production baseline for anti-money-laundering detection, and Revolut wrote this into their paper. The reason is that AML is a relational problem. You catch laundering by looking across users and across accounts, and PRAGMA processes each user history in isolation. The lesson generalises: foundation models on individual ledgers are not graph-aware, and the production AML stack at any large bank includes graph-aware components that PRAGMA cannot replace. Knowing the limit is more useful than the headline gains.
## How this compares to Nubank
Nubank's nuFormer, published in July 2025, makes the opposite architectural choice. It is a causal GPT-style decoder pre-trained with next-token prediction, with a [joint fusion](https://building.nubank.com/fine-tuning-transaction-user-models/) finetuning step that bolts a [DCNv2](https://arxiv.org/abs/2008.13535) tabular network onto the same gradient graph. The reported lift is **+1.25%** in test AUC on a single recommendation task, and a **4.4%** reduction in user churn measured in production. Smaller numbers than PRAGMA, but Nubank published a real production deployment outcome. PRAGMA's results are still backtests.
The two papers disagree on almost everything that is fun to argue about. Architecture: decoder versus encoder. Task scope: one task versus six. The role of static profile state: collapsed into the sequence versus given its own branch. What they agree on: Hand-crafted feature engineering can be replaced by self-supervised representation learning on raw transaction sequences, and doing so produces material lifts on real banking problems. The architectural debate is downstream of that.
The broader literature is moving the same way. [TransactionGPT](https://arxiv.org/abs/2511.08939) (Dou et al., 2025) introduces a 3D transformer for billion-scale payment trajectories aimed at anomaly detection. [FinBERT](https://arxiv.org/abs/1908.10063), [BloombergGPT](https://arxiv.org/abs/2303.17564), and [FinGPT](https://arxiv.org/abs/2306.06031) cover the text side. [Time-LLM](https://arxiv.org/abs/2310.01728) and [Chronos](https://arxiv.org/abs/2403.07815) cover numerical time series. PRAGMA and nuFormer are the two papers that target the actual structured event ledger sitting inside a retail bank, which is the asset that matters for credit, fraud, and product decisions.
## Outlook
There is no public checkpoint. Revolut and Nubank both keep their weights inside their production stack, which is the right business decision and the wrong scientific one. You cannot run PRAGMA on your own data. You can only read the paper and decide whether the recipe is reproducible.
I think it is. The paper is detailed enough to rebuild from. The tokenisation scheme is fully specified. The architecture diagram is precise enough to follow. They even document the optimiser, [Muon](https://kellerjordan.github.io/posts/muon/) plus AdamW, and the hardware, 32 H100s for the 1B variant. The constraint is the pre-training corpus, not the model.
So the next project on this site is a faithful PRAGMA reimplementation at the small (10M) scale, trained on a synthetic or open-licensed transaction dataset, evaluated on a subset of the downstream tasks where public benchmarks exist. I will write that up here in instalments, including what works, what breaks, and where the paper is silent. The codebase will land in a public repository as I build it.
---
## Frequently Asked Questions
### What is PRAGMA?
PRAGMA is a family of encoder-only transformer foundation models built by Revolut Research and NVIDIA for multi-source banking event sequences. Published as arXiv:2604.08649 in April 2026, it comes in three sizes (10M, 100M, 1B parameters) pretrained with masked language modelling on 24 billion user events.
### How does PRAGMA differ from Nubank's nuFormer?
PRAGMA is a bidirectional encoder pretrained with masked modelling, evaluated on six discriminative tasks. nuFormer is a causal decoder pretrained with next-token prediction, evaluated on a single recommendation task with a separate tabular DNN at fine-tuning time. Both replace hand-crafted tabular features, but make opposite architectural choices.
### Can I use PRAGMA on my own data?
Not directly. Neither Revolut nor Nubank releases weights, code, or checkpoints. Both are internal production models trained on private banking data. The papers are detailed enough to reimplement, which is the path I am taking as a follow-up project.
### Why does PRAGMA fail on anti-money-laundering?
AML is a relational problem: you catch laundering by looking across users and across accounts. PRAGMA processes each user history in isolation, so it loses 47.1% on F-0.5 against the production AML baseline. The lesson generalises to any banking foundation model: per-user encoders are not graph-aware, and graph-aware components in the production AML stack cannot be replaced by them.
### How does PRAGMA compare to Stripe's Payments Foundation Model?
Stripe's PFM and PRAGMA both treat transaction sequences as the primary input and produce embeddings that feed downstream models. Stripe's model targets payment-flow understanding for fraud and risk on Stripe's own ledger. PRAGMA targets a broader retail-banking surface (credit, fraud, churn, communication, recommendation) on Revolut's ledger. The architectural details and evaluation tasks differ, but both make the same convergent bet: foundation models for tabular transaction streams beat hand-crafted features.
---
*Philipp D. Dubach — [http://philippdubach.com/](http://philippdubach.com/) — 2026*