Last week I published a Hacker News title sentiment analysis based on the Attention Dynamics in Online Communities paper I have been working on. The discussion on Hacker News raised the obvious question: can you actually predict what will do well here?
 The honest answer is: partially. Timing matters. News cycles matter. Who submits matters. Weekend versus Monday morning matters. Most of these factors aren’t in the title. But titles aren’t nothing either. “Show HN” signals something. So does phrasing, length, and topic selection. The question becomes: how much signal can you extract from 80 characters?
The honest answer is: partially. Timing matters. News cycles matter. Who submits matters. Weekend versus Monday morning matters. Most of these factors aren’t in the title. But titles aren’t nothing either. “Show HN” signals something. So does phrasing, length, and topic selection. The question becomes: how much signal can you extract from 80 characters?
Hacker News (HN) is a social news website focusing on computer science and entrepreneurship. It is run by the investment fund and startup incubator Y Combinator.
This isn’t new territory. Max Woolf built a Reddit submission predictor back in 2017, and ontology2 trained an HN classifier using logistic regression on title words. Both found similar ceilings; around 0.76 AUC with classical approaches. I wanted to see what modern transformers could add.
The baseline was DistilBERT, fine-tuned on 90,000 HN posts. ROC AUC of 0.654, trained in about 20 minutes on a T4 GPU. Not bad for something that only sees titles. Then RoBERTa with label smoothing pushed it to 0.692. Progress felt easy.
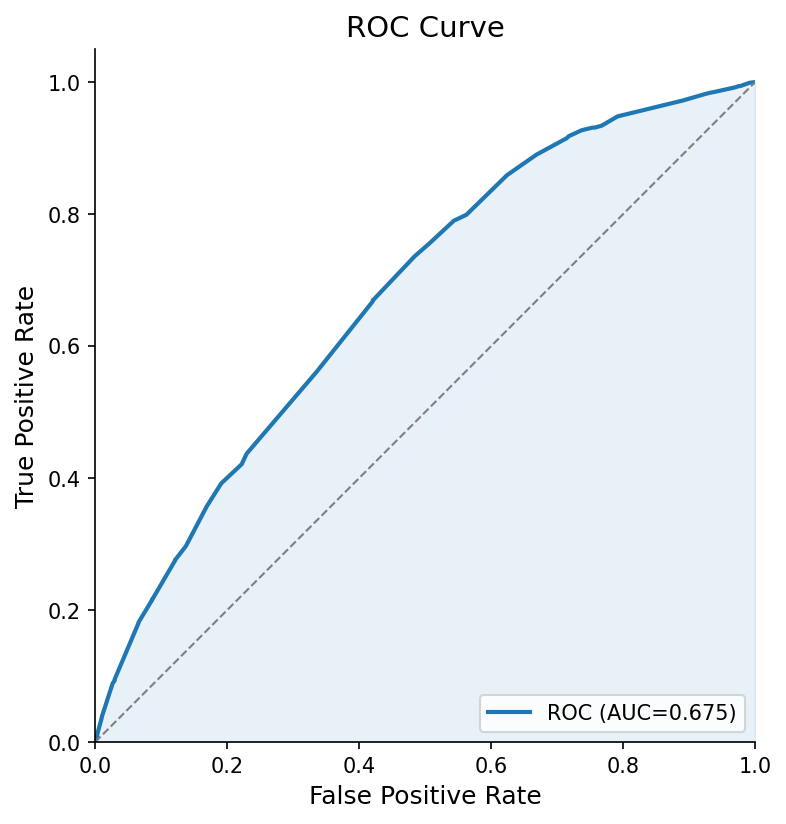
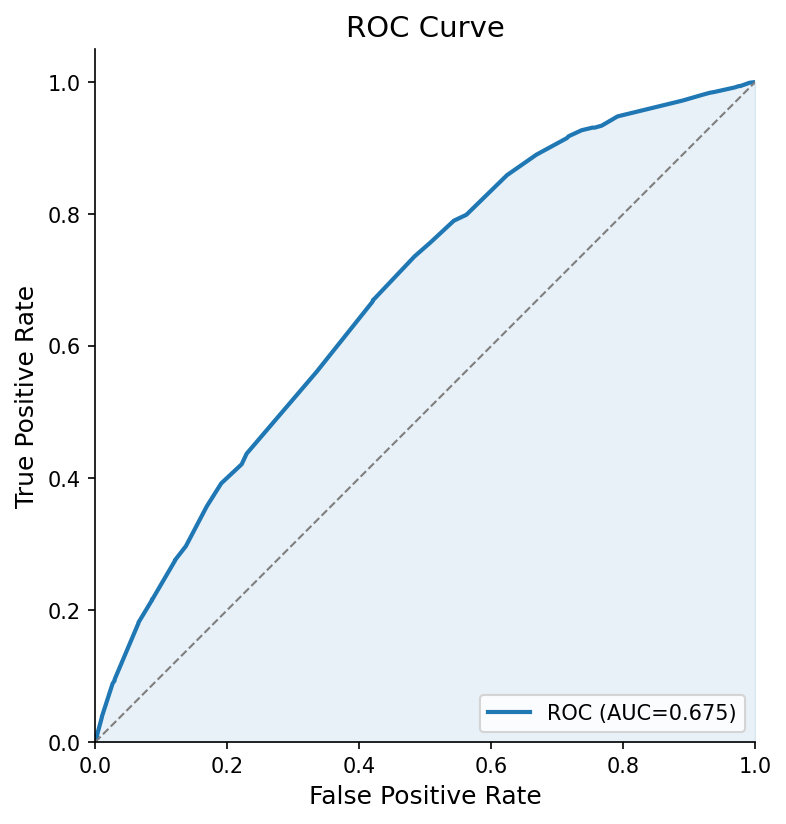 What if sentence embeddings captured something classification heads missed? I built an ensemble: SBERT for semantic features, RoBERTa for discrimination, weighted average at the end. The validation AUC jumped to 0.714.
What if sentence embeddings captured something classification heads missed? I built an ensemble: SBERT for semantic features, RoBERTa for discrimination, weighted average at the end. The validation AUC jumped to 0.714.
The problem was hiding in the train/test split. I’d used random sampling. HN has strong temporal correlations: topics cluster, writing styles evolve, news cycles create duplicates. A random split let the model see the future. SBERT’s semantic embeddings matched near-duplicate posts across the split perfectly.
When I switched to a strict temporal split, training on 2022-early 2024 and testing on late 2024 onward, the ensemble dropped to 0.693. More revealing: the optimal SBERT weight went from 0.35 to 0.10. SBERT was contributing almost nothing. The model had memorized temporal patterns, not learned to predict.
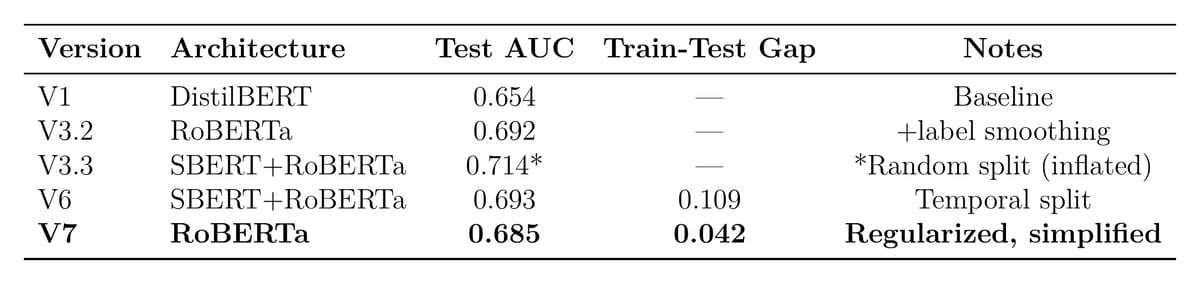
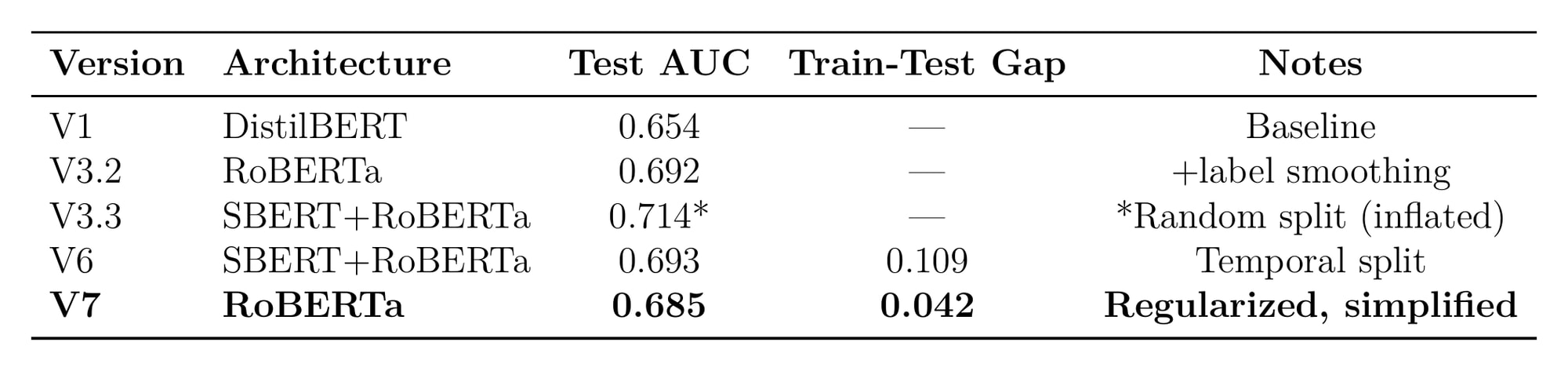
 I kept RoBERTa, added more regularization, dropped from 0.1 to 0.2 dropout, weight decay from 0.01 to 0.05, froze the lower six transformer layers. The model got worse at fitting training data. Train AUC dropped from 0.803 to 0.727.
I kept RoBERTa, added more regularization, dropped from 0.1 to 0.2 dropout, weight decay from 0.01 to 0.05, froze the lower six transformer layers. The model got worse at fitting training data. Train AUC dropped from 0.803 to 0.727.
But the train-test gap collapsed from 0.109 to 0.042. That’s a 61% reduction in overfitting. Test AUC of 0.685 versus the ensemble’s 0.693, a difference that vanishes once you account for confidence intervals. And now inference runs on a single model, half the latency, no SBERT dependency, 500MB instead of 900MB.
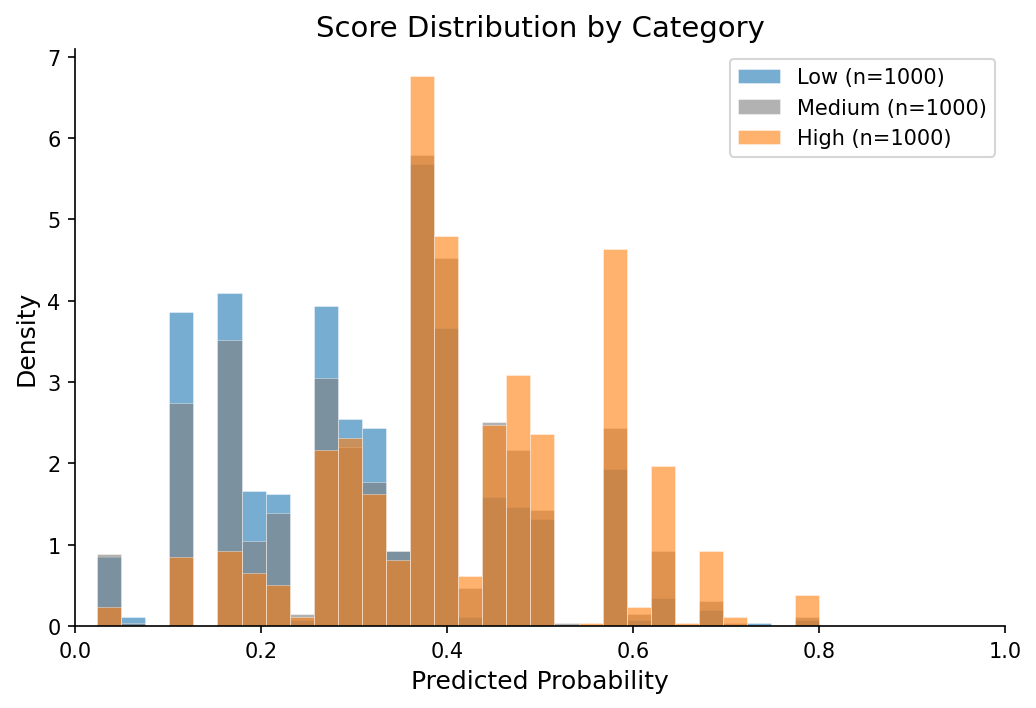
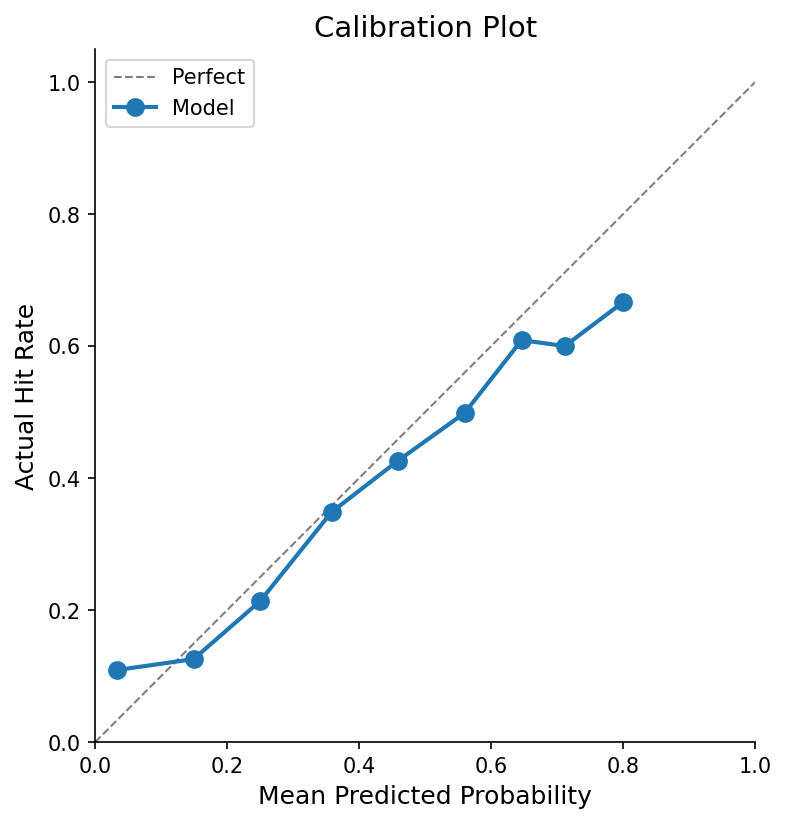
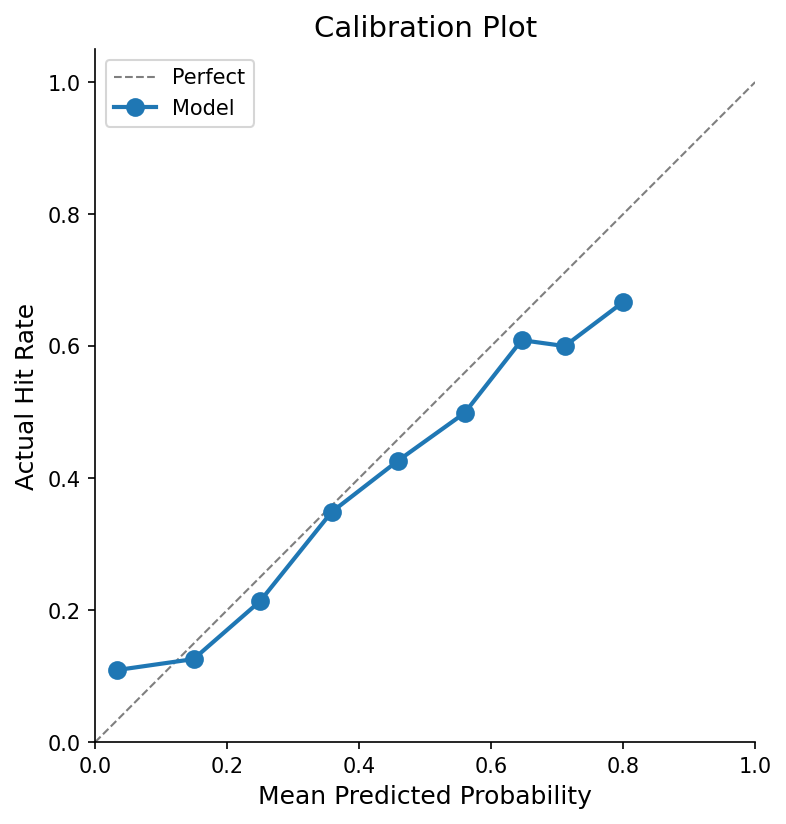
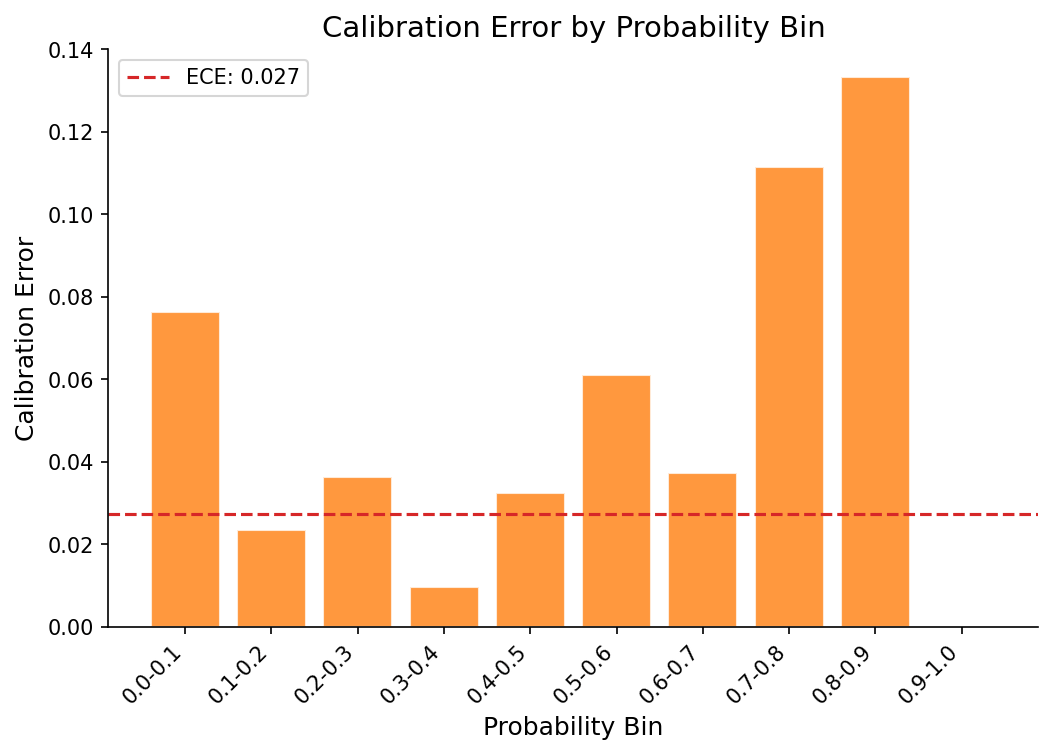
 The other lesson was calibration. A model that says 0.8 probability should mean “70% of posts I give this score actually hit 100 points.” Neural networks trained on cross-entropy don’t do this naturally. They’re overconfident. I used isotonic regression on the validation set to fix the mapping. Expected calibration error (ECE) measures this gap:
The other lesson was calibration. A model that says 0.8 probability should mean “70% of posts I give this score actually hit 100 points.” Neural networks trained on cross-entropy don’t do this naturally. They’re overconfident. I used isotonic regression on the validation set to fix the mapping. Expected calibration error (ECE) measures this gap:
where you bin predictions by confidence, then measure how far off the actual accuracy is from the predicted confidence in each bin. ECE went from 0.089 to 0.043. Now when the model says 0.4, it’s telling the truth.
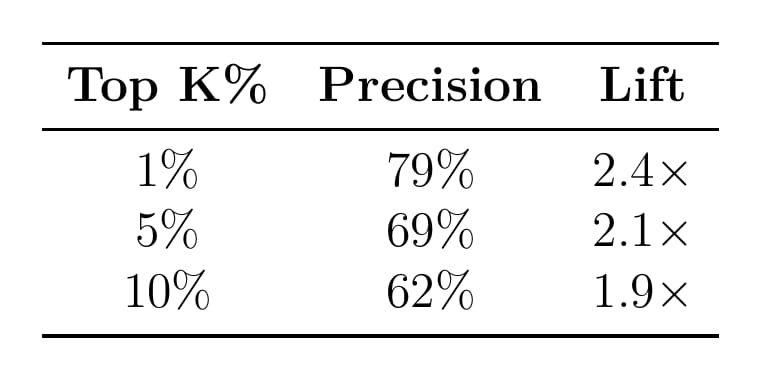
In practice, the model provides meaningful lift. If you only look at the top 10% of predictions by score, 62% of them are actual hits, roughly 1.9x better than random selection:
 About training speed: I used the NVIDIA H100 GPU, which runs around 18x more expensive than the T4 per hour on hosted (Google Colab) runtimes. A sensible middle ground would be an A100 (40 or 80GB VRAM) or L4, training 3-5x faster than T4, maybe 5-7 minutes instead of 20-30. But watching epochs fly by at ~130 iterations per second after coming from T4’s ~3 iterations per second was a different experience.
About training speed: I used the NVIDIA H100 GPU, which runs around 18x more expensive than the T4 per hour on hosted (Google Colab) runtimes. A sensible middle ground would be an A100 (40 or 80GB VRAM) or L4, training 3-5x faster than T4, maybe 5-7 minutes instead of 20-30. But watching epochs fly by at ~130 iterations per second after coming from T4’s ~3 iterations per second was a different experience. 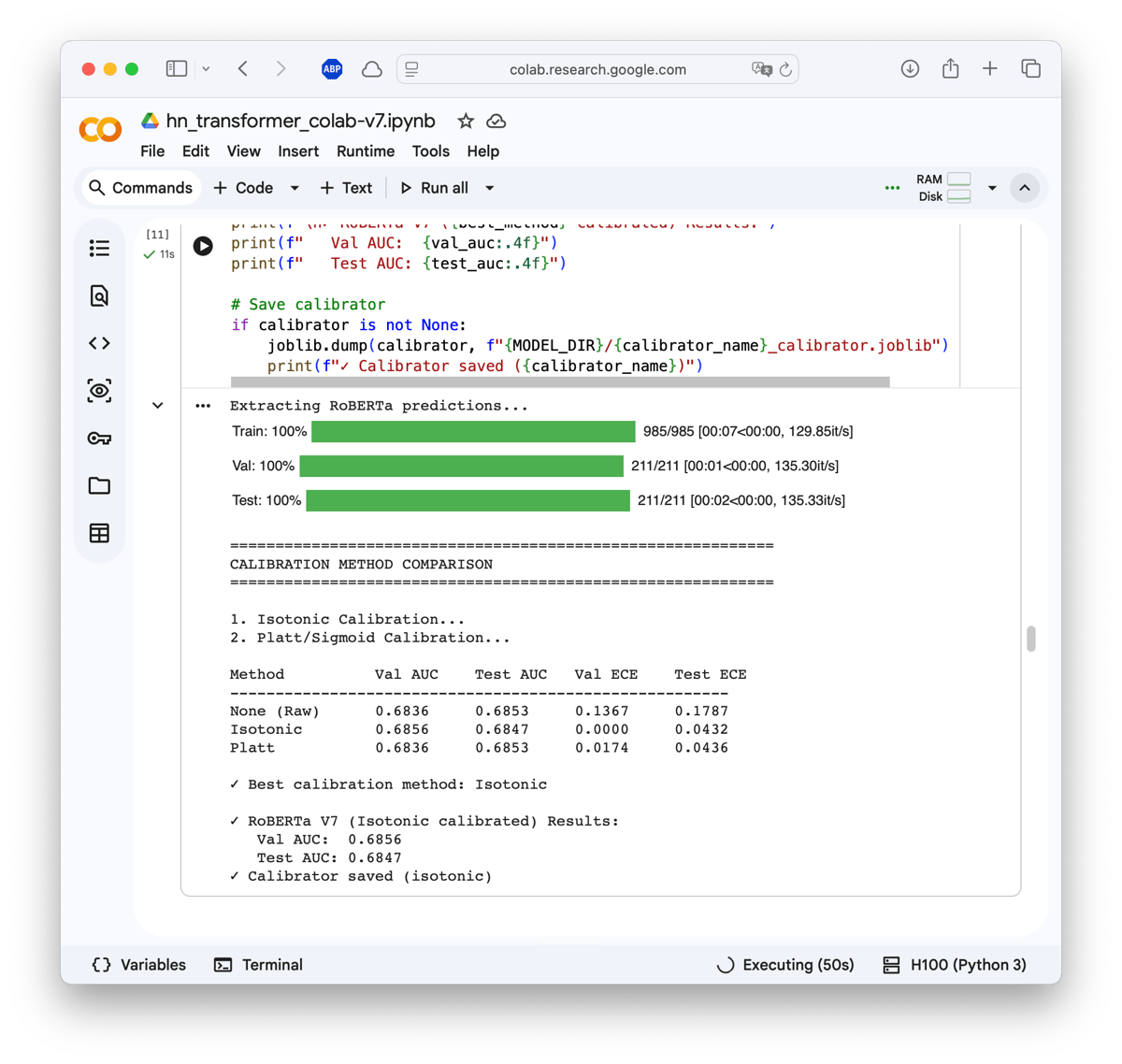
 The model learned some intuitive patterns. “Show HN” titles score higher. Deep technical dives do well. Generic news aggregation doesn’t. Titles between 40-80 characters perform better than very short or very long ones. Some of this probably reflects real engagement patterns. Some of it is noise the model hasn’t been sufficiently regularized to ignore.
The model learned some intuitive patterns. “Show HN” titles score higher. Deep technical dives do well. Generic news aggregation doesn’t. Titles between 40-80 characters perform better than very short or very long ones. Some of this probably reflects real engagement patterns. Some of it is noise the model hasn’t been sufficiently regularized to ignore.
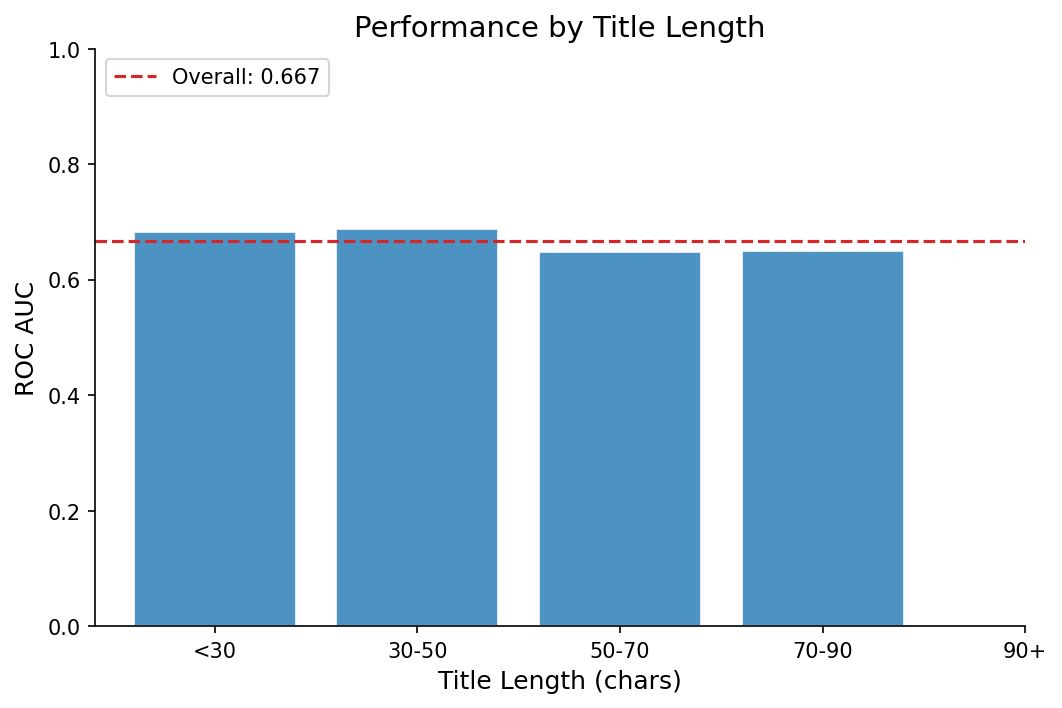
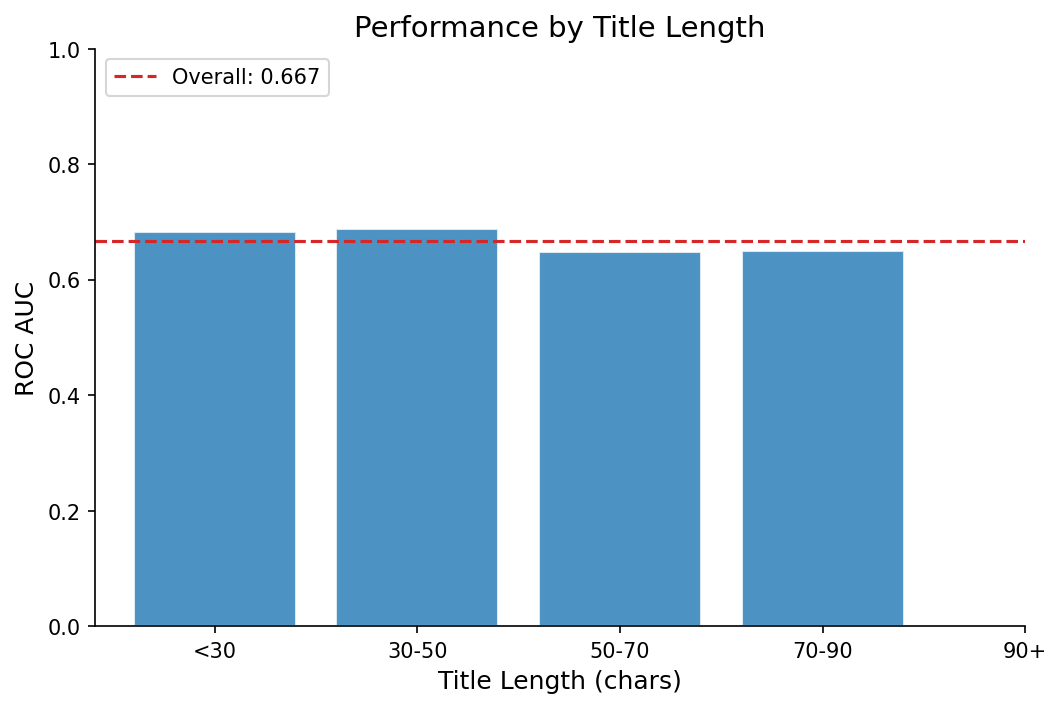
Running a few titles through the model shows what it picks up on:

 Vague claims score low. Specificity helps. First-person “I built” framing does well, which matches what actually gets upvoted. The model isn’t learning to game HN; it’s learning what HN already rewards.
Vague claims score low. Specificity helps. First-person “I built” framing does well, which matches what actually gets upvoted. The model isn’t learning to game HN; it’s learning what HN already rewards.
The model now runs, scoring articles in an RSS reader pipeline I built. Does it help? Mostly. I still click on things marked low probability. But the high-confidence predictions are usually right. It’s a filter, not an oracle.
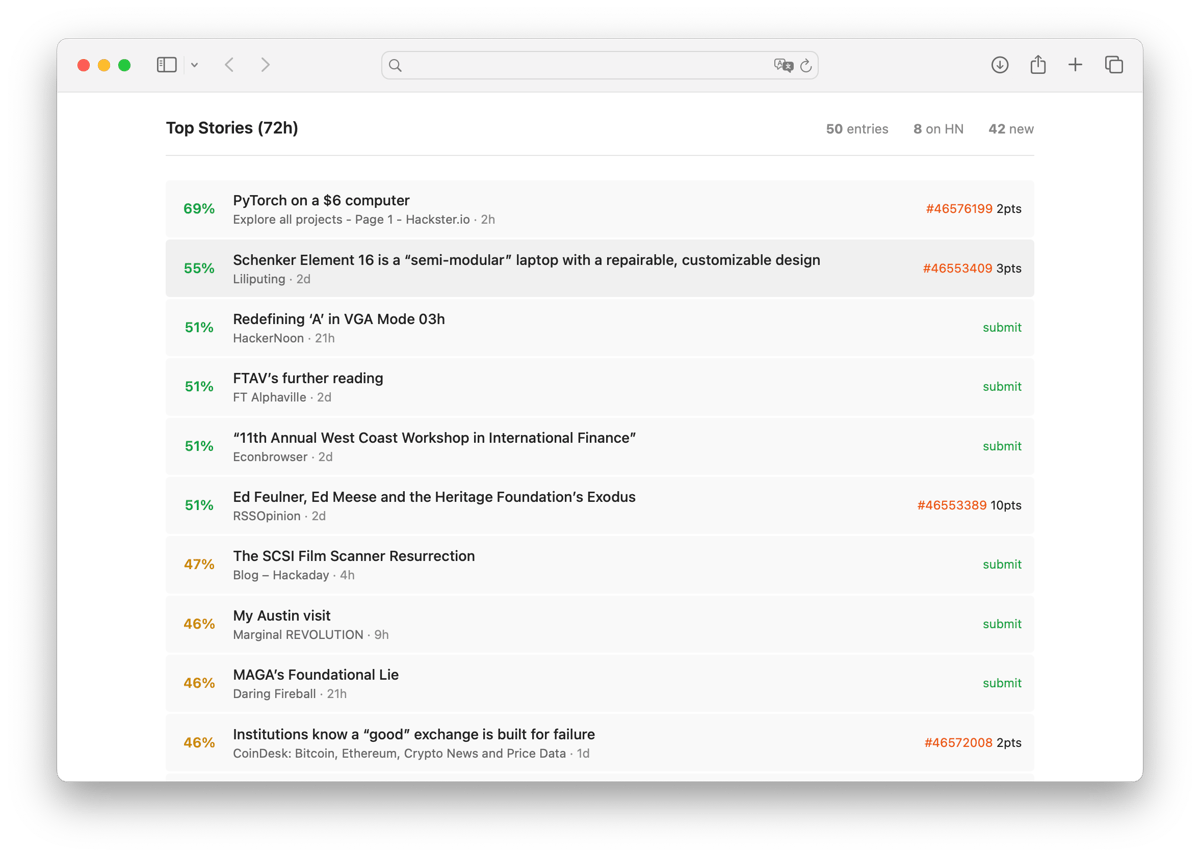
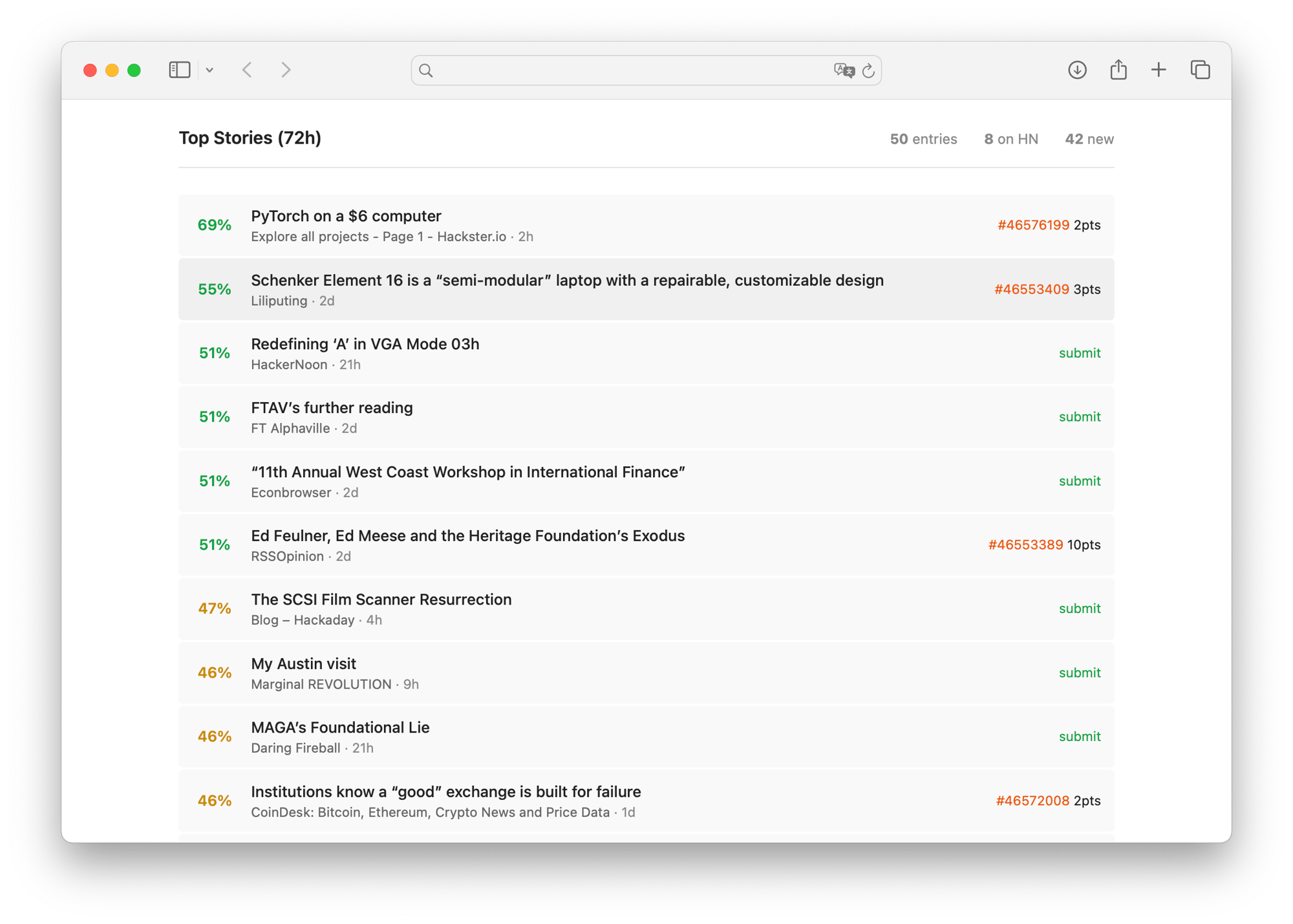
Model on HuggingFace — Download the weights and run inference locally
RSS Reader Pipeline — Full scoring pipeline with feed aggregation
Training Notebook — Colab-ready notebook with the complete training code
On a side note: The patterns here aren’t specific to Hacker News or online communities. Temporal leakage shows up whenever you’re predicting something that evolves over time: credit defaults, client churn, market regimes. The fix is the same: validate on future data, not random holdouts. Calibration matters anywhere probabilities drive decisions. A loan approval model that says “70% chance of repayment” needs that number to mean something. Overfitting to training data is how banks end up with models that look great in backtests and fail in production.
I’ve built similar systems for other domains: sentiment-based trading signals, glycemic response prediction, portfolio optimization. The ML fundamentals transfer. What changes is the domain knowledge needed to avoid the obvious mistakes, like training on data that wouldn’t have been available at prediction time, or trusting metrics that don’t reflect real-world performance.