# The Last Architecture Designed by Hand
**Author:** Philipp D. Dubach | **Published:** March 16, 2026
**Categories:** AI, Tech
**Keywords:** what comes after transformers, transformer architecture limits, AI architecture 2026, Mamba vs transformer, hybrid AI architecture, post-transformer architecture, AlphaEvolve AI research, transformer quadratic scaling, diffusion language models, mixture of experts MoE, AI recursive self-improvement, LLM hallucination mathematical proof, DeepSeek V3 training cost, inference compute scaling, Jamba hybrid architecture, test-time compute scaling, state space models vs transformers, transformer replacement 2026
## Key Takeaways
- Mathematical proofs now show that quadratic scaling, hallucination, and positional bias are structural properties of the transformer, not fixable with better training data or RLHF.
- Over 60% of frontier models released in 2025 use Mixture of Experts, and production hybrids like Jamba and Qwen3-Next blend attention with state space models at 3x throughput.
- AlphaEvolve found a 23% speedup inside Gemini's own architecture, cutting training time by 1% and recovering 0.7% of Google's total compute resources.
- OpenAI's inference spending hit $2.3 billion in 2024, 15x what they spent training GPT-4.5, meaning the economic center of gravity has already shifted from training to inference.
---
> I bet there is another new architecture to find that is gonna be as big of a gain as transformers were over LSTMs.
Sam Altman, the CEO of the company most invested in the transformer is telling a room of students it isn't the final form. So what comes after the transformer? He's probably right that something will, and the evidence is no longer anecdotal. Several recent papers have proved that the transformer's worst properties are structural, not engineering problems to be fixed with better data or more compute, but mathematical lower bounds.
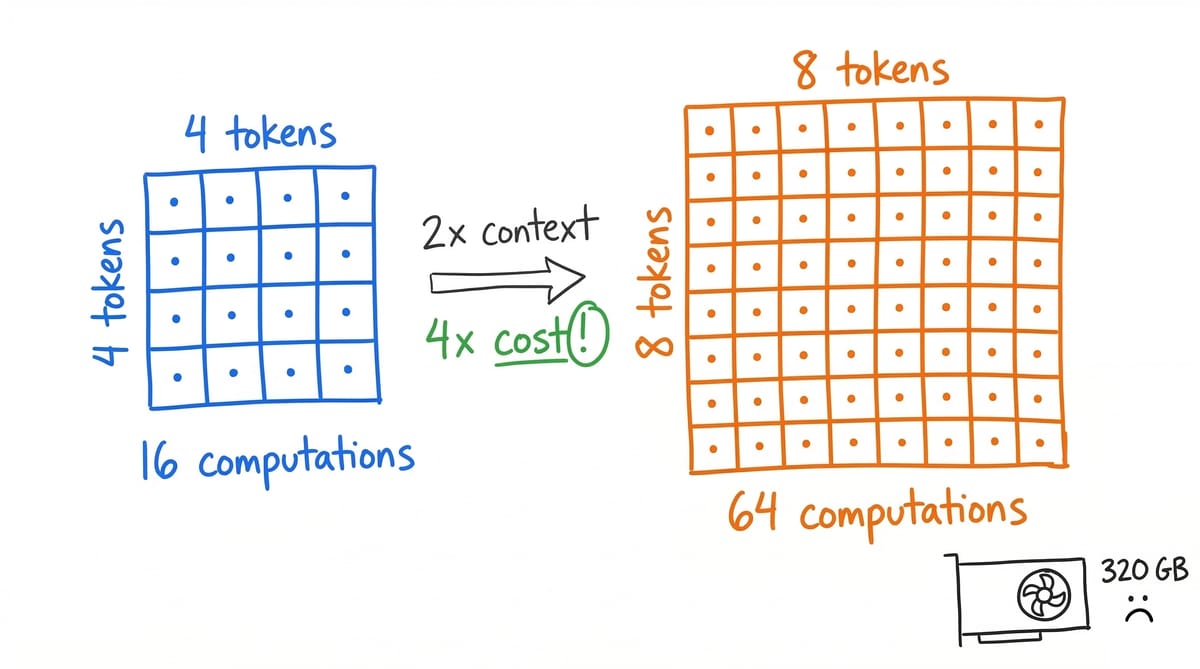
The transformer, born from the 2017 paper ["Attention Is All You Need,"](https://arxiv.org/abs/1706.03762) took us from barely-coherent GPT-2 to GPT-4 in five years. An extraordinary run. But [Duman Keles et al.](https://arxiv.org/abs/2209.04881) proved that O(n²) attention complexity isn't an implementation detail. It's a necessary lower bound unless a foundational conjecture in complexity theory turns out to be wrong. Double the context, quadruple the cost. The KV cache for a 70B model at one-million-token context eats roughly **320 GB** of GPU memory. Most hardware can't hold it.
The problems run deeper than compute costs. [Kalai and Vempala](https://arxiv.org/abs/2311.14648) proved that any calibrated language model *must* hallucinate at a certain rate. A [2025 follow-up](https://arxiv.org/abs/2509.04664) goes further: no computable LLM can be universally correct on unbounded queries. Not fixable with better training data. Not fixable with RLHF. A statistical property of how these models generate text.
On reasoning: [Dziri et al.](https://arxiv.org/abs/2305.18654) showed transformers collapse multi-step reasoning into pattern matching. Performance drops exponentially as task complexity rises. GPT-4 gets **59%** on 3-digit multiplication. [Chowdhury](https://arxiv.org/abs/2603.10123) proved the "lost in the middle" problem, models performing 20-30% worse on information buried mid-context, is a geometric property of the architecture itself. Present at initialization already, before any training occurs.
These are theorems. The architecture that runs every frontier AI system has a ceiling, and the ceiling is proved.
## The post-transformer stack is already in production
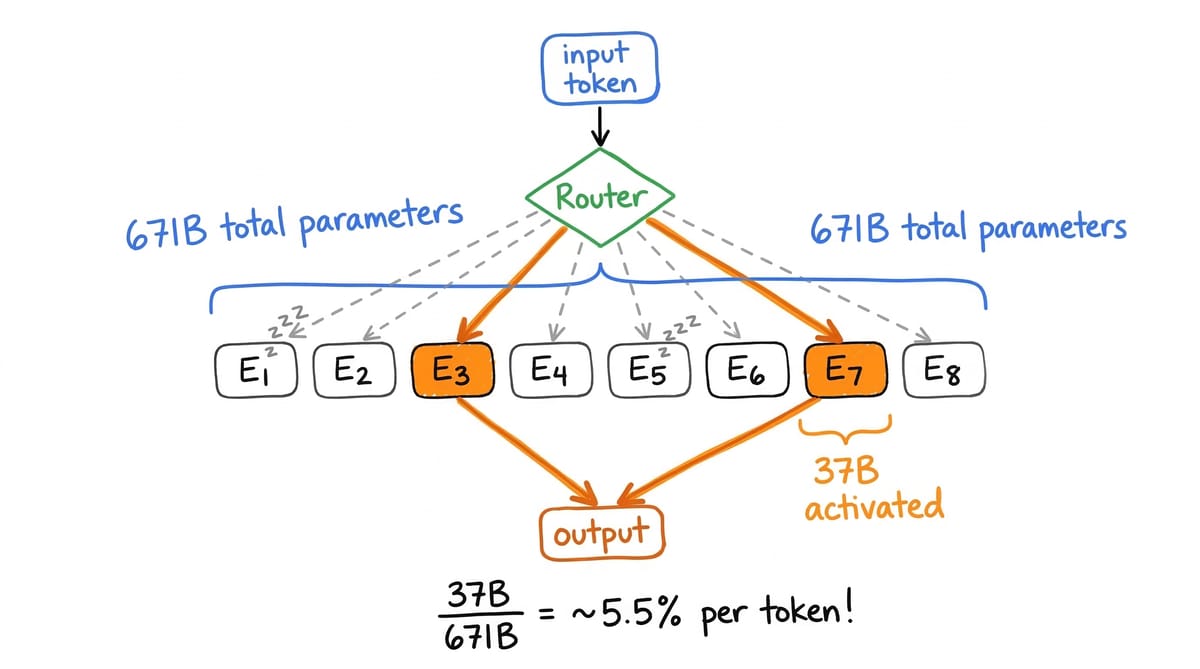
A [survey by Fichtl et al.](https://arxiv.org/abs/2510.05364) checked the top 10 models on every major benchmark. Zero were non-transformer. The transformer is still winning on the leaderboards. But the field is moving toward hybrid architectures. Over **60%** of frontier models released in 2025 already use Mixture of Experts. [DeepSeek-V3](https://arxiv.org/abs/2412.19437) has 671B total parameters but activates only 37B per token. It trained for **2.788 million H800 GPU hours**, a fraction of what a comparable dense model would require, and matched frontier closed-source performance. By late 2025, [DeepSeek-V3.2 reportedly hit GPT-5-level performance at 90% lower training cost](https://c3.unu.edu/blog/inside-deepseeks-end-of-year-ai-breakthrough-what-the-new-models-deliver). MoE doesn't replace the transformer. It changes the economics so radically that it's arguably the single biggest practical advance since the original architecture.
The more interesting part is what happens when you blend attention with state space models. [Gu and Dao (2024)](https://goombalab.github.io/blog/2024/mamba2-part1-model/) proved SSMs and attention are mathematically dual: two views of the same computation. That theoretical result is showing up in production. [AI21's Jamba](https://www.ai21.com/jamba/) runs a 1:7 attention-to-Mamba ratio and gets **256K** context at **3x** throughput over Mixtral. Alibaba's Qwen3-Next shipped the first top-tier model with a hybrid backbone: [Gated DeltaNet](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/08_deltanet/README.md) for linear attention at a 3:1 ratio with full attention. Microsoft's Phi-4-mini-flash-reasoning is 75% Mamba layers with **10x** throughput at **2-3x** lower latency.
Diffusion language models are the wild card. [LLaDA](https://arxiv.org/abs/2502.09992), the first 8B-parameter diffusion LLM, treats text generation as denoising rather than sequential token prediction. It matches Llama3-8B and does something no autoregressive model can: it solves the "reversal curse," outperforming GPT-4o on reversal tasks. [Gemini Diffusion](https://medium.com/@ML-today/diffusion-models-for-language-from-early-promise-to-a-bold-new-frontier-with-llada-and-the-rise-of-ee80c7ffb8fa) hit **1,479 tokens per second**. Over 50 papers on diffusion LLMs appeared in 2025. If parallel generation works reliably at scale, inference economics change completely.
[Alman and Yu](https://arxiv.org/pdf/2510.05364) proved there are tasks where every subquadratic alternative has a fundamental theoretical gap. That's the strongest mathematical argument for why hybrids, not clean replacements, are what comes next.
## The search is no longer human-speed
The part of this I find most interesting is the recursion. AI systems are now running the search for their own architectural successors.
[AlphaEvolve](https://deepmind.google/blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/) an evolutionary coding agent built on Gemini 2.0 found a way to multiply 4x4 complex matrices in 48 scalar multiplications: the first improvement on Strassen's 56-year-old bound. Across [50+ open math problems](https://www.infoq.com/news/2025/05/google-alpha-evolve/), it matched the best known solutions 75% of the time and beat them 20% of the time. The recursive part: AlphaEvolve found a [23% speedup on a kernel inside Gemini's own architecture](https://cloud.google.com/blog/products/ai-machine-learning/alphaevolve-on-google-cloud), cutting Gemini's training time by 1% and recovering **0.7%** of Google's total compute. Gemini making Gemini faster.
[Karpathy's AutoResearch](https://www.marktechpost.com/2026/03/08/andrej-karpathy-open-sources-autoresearch-a-630-line-python-tool-letting-ai-agents-run-autonomous-ml-experiments-on-single-gpus/), released March 7, 2026, is a 630-line Python script that lets an AI agent modify training code, run 5-minute experiments, check results, and iterate. He pointed it at his own highly-tuned "Time to GPT-2" codebase. The agent found about 20 additive improvements that transferred to larger models, cutting the metric by **11%**. [Shopify CEO Tobi Lutke tried it overnight](https://officechai.com/ai/andrej-karpathys-autoresearch-project-lets-agents-run-100-ai-research-experiments-while-you-sleep/): 37 experiments, 19% validation improvement, a 0.8B model outperforming a 1.6B one. [Sakana AI's AI Scientist v2](https://github.com/SakanaAI/AI-Scientist-v2) went further and produced the first AI-authored paper accepted through standard peer review. [OpenAI said publicly in late 2025](https://controlai.news/p/the-ultimate-risk-recursive-self) that it's researching how to safely build AI systems capable of recursive self-improvement. Two years ago this was a thought experiment.
## What the hardware decides
The transformer won not because attention was theoretically prettier than recurrence. It won because it parallelized well on GPUs. Whatever comes next has to clear the same bar.
Pre-training scaling for dense transformers is flattening. [OpenAI spent at least $500 million per major training run on Orion](https://fortune.com/2025/02/25/what-happened-gpt-5-openai-orion-pivot-scaling-pre-training-llm-agi-reasoning/). The model hit GPT-4 performance after 20% of training; the remaining 80% gave diminishing returns. They downgraded it from GPT-5 to GPT-4.5. [Sutskever](https://artificialintelligencemonaco.substack.com/p/ilya-sutskever-on-superintelligence) at NeurIPS 2024: "Pre-training as we know it will end. The data is not growing because we have but one internet." His startup SSI has [raised to a $32 billion valuation with about 20 employees and zero revenue](https://www.arturmarkus.com/ilya-sutskevers-ssi-raises-1b-at-30b-valuation-with-zero-revenue-6x-jump-in-5-months-redefines-ai-investment-logic/). A bet that the next leap requires something architecturally new.
But test-time compute opened a different axis entirely. OpenAI's o3 hit **87.5%** on ARC-AGI, beating most humans. DeepSeek-R1 matched o1-level reasoning at **70%** lower cost. [OpenAI's inference spending reached $2.3 billion in 2024](https://aibusiness.com/language-models/ai-model-scaling-isn-t-over-it-s-entering-a-new-era): **15x** what they spent training GPT-4.5. [Dario Amodei](https://www.dwarkesh.com/p/dario-amodei) at Morgan Stanley in March 2026: "We do not see hitting the wall. We don't see a wall." He's talking about this axis, inference-time compute and RL from verifiable rewards, not about pre-training bigger dense models. The Densing Law now shows capability per parameter doubling every **3.5 months** through better data, MoE, and distillation. Last year's frontier, matched with a fraction of the parameters.
Inference demand is projected to [exceed training demand by 118x](https://v-chandra.github.io/on-device-llms/). Global data center power is heading toward [945 TWh by 2030](https://www.iea.org/reports/energy-and-ai/executive-summary), roughly Japan's total electricity consumption. An architecture that scores 2x better on benchmarks but runs 3x worse at inference won't win. What ships is whatever fits the hardware. The transformer isn't going away. It's becoming one component in a larger stack: attention for recall, SSMs for cheap sequence processing, MoE for capacity, maybe diffusion for parallel output. [Jamba](https://www.ai21.com/jamba/), [Hymba](https://arxiv.org/html/2411.13676v1), and Qwen3-Next already ship this way. That's not a prediction. It's what's in production.
How fast the stack evolves is the open question. The answer, given AlphaEvolve and AutoResearch and AI Scientist v2, is faster than any previous architectural transition. I don't know whether the transformer remains the dominant layer for two years or five. But I'm fairly confident that whatever comes next, humans won't have designed it alone.
---
## Frequently Asked Questions
### What are the mathematical limits of the transformer architecture?
Several recent proofs demonstrate structural constraints. Duman Keles et al. (2023) proved O(n²) attention complexity is a necessary lower bound. Kalai and Vempala (STOC 2024) proved any calibrated language model must hallucinate at a certain rate. Chowdhury (2026) showed the lost-in-the-middle problem is geometric, present at initialization before training. These are not engineering challenges to be fixed with better data.
### What will replace the transformer architecture?
Not a single replacement but a hybrid stack. Over 60% of frontier models already use Mixture of Experts. Production systems like AI21's Jamba, Alibaba's Qwen3-Next, and Microsoft's Phi-4-mini-flash-reasoning blend attention with state space models (Mamba) for 3-10x throughput gains. Diffusion language models like LLaDA offer a wilder alternative, generating text through denoising rather than sequential token prediction.
### Can AI systems design their own replacement architecture?
It is already happening. DeepMind's AlphaEvolve found a 23% kernel speedup inside Gemini's own architecture. Karpathy's AutoResearch discovered about 20 improvements on his own highly-tuned codebase, cutting the metric by 11%. Sakana AI's AI Scientist v2 produced the first AI-authored paper accepted through standard peer review. The timeline from thought experiment to working systems was faster than most expected.
### Has AI pre-training scaling hit a wall?
For dense transformers, evidence points to flattening. OpenAI's Orion model hit GPT-4 performance after just 20% of training, with diminishing returns for the remaining 80%. But test-time compute opened a different axis: inference spending hit $2.3 billion at OpenAI in 2024, 15x training costs. The Densing Law shows capability per parameter doubling every 3.5 months through MoE, distillation, and better data curation.
---
*Philipp D. Dubach — [http://philippdubach.com/](http://philippdubach.com/) — 2026*