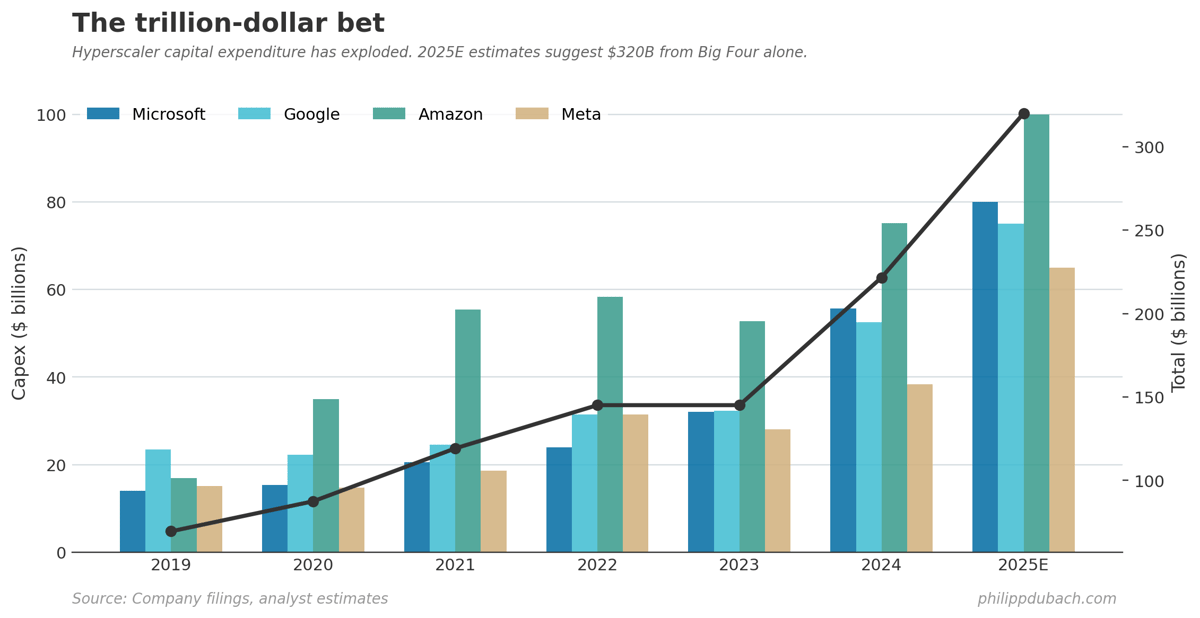
Sara Hooker’s paper arrived with impeccable timing. On the slow death of scaling dropped just as hyperscalers are committing another $500 billion to GPU infrastructure, bringing total industry deployment into the scaling thesis somewhere north of a trillion dollars. I’ve been tracking these capital flows for my own portfolio. Either Hooker is early to a generational insight or she’s about to be very publicly wrong.
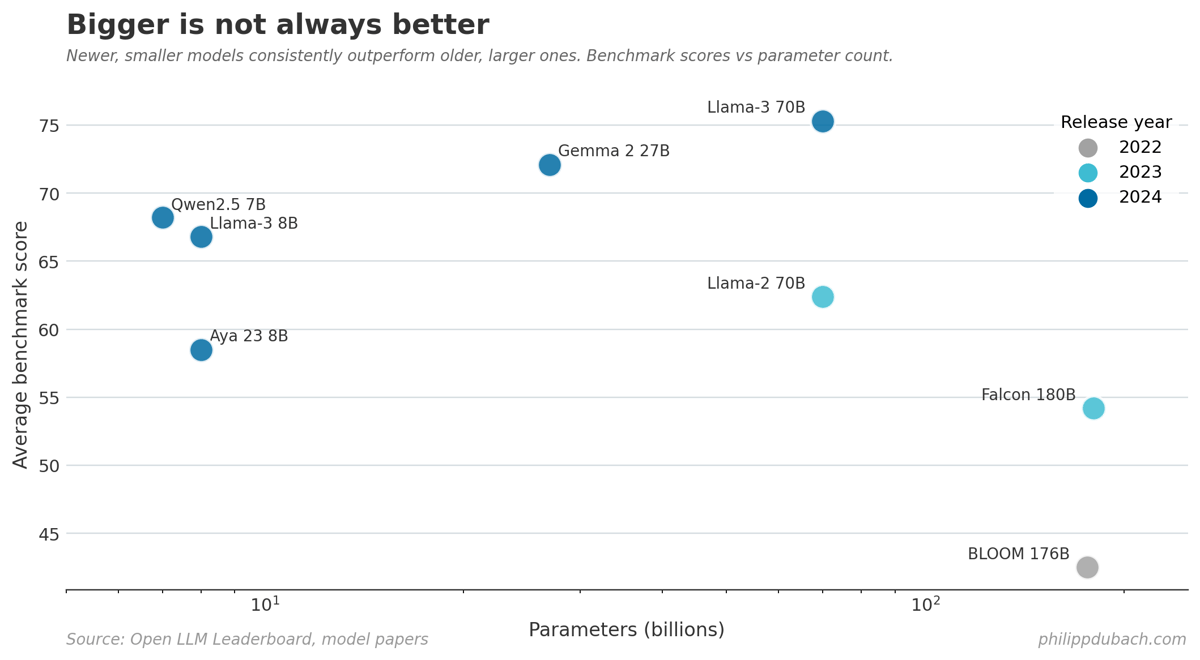
 The core argument is very simple: bigger is not always better. Llama-3 8B outperforms Falcon 180B. Aya 23 8B beats BLOOM 176B despite having only 4.5% of the parameters. These are not isolated flukes. Hooker plots submissions to the Open LLM Leaderboard over two years and finds a systematic trend where compact models consistently outperform their bloated predecessors. The bitter lesson, as Rich Sutton framed it, was that brute force compute always wins. Hooker’s counter is that maybe we’ve been held hostage to “a painfully simple formula” that’s now breaking down.
The core argument is very simple: bigger is not always better. Llama-3 8B outperforms Falcon 180B. Aya 23 8B beats BLOOM 176B despite having only 4.5% of the parameters. These are not isolated flukes. Hooker plots submissions to the Open LLM Leaderboard over two years and finds a systematic trend where compact models consistently outperform their bloated predecessors. The bitter lesson, as Rich Sutton framed it, was that brute force compute always wins. Hooker’s counter is that maybe we’ve been held hostage to “a painfully simple formula” that’s now breaking down.
 Scaling laws, she notes, only reliably predict pre-training test loss. When you look at actual downstream performance, the results are “murky or inconsistent.” The term “emergent properties” gets thrown around to describe capabilities that appear suddenly at scale, but Hooker points out this is really just a fancy way of admitting we have no idea what’s coming. If your scaling law can’t predict emergence, it’s not much of a law.
Scaling laws, she notes, only reliably predict pre-training test loss. When you look at actual downstream performance, the results are “murky or inconsistent.” The term “emergent properties” gets thrown around to describe capabilities that appear suddenly at scale, but Hooker points out this is really just a fancy way of admitting we have no idea what’s coming. If your scaling law can’t predict emergence, it’s not much of a law.
Gary Marcus has been making a related argument from a different angle. The cognitive scientist, whose 2001 book predicted hallucination problems, calls LLMs “glorified memorization machines” that work because the internet contains answers to most common queries. His framing is less academic and more market-oriented: the jump from GPT-1 to GPT-4 showed obvious qualitative leaps requiring no benchmarks. The jump from GPT-4 to GPT-5? Marginal improvements requiring careful measurement. The textbook definition of diminishing returns.
The market signals are worth watching. According to Goldman Sachs data, hedge fund short interest in utilities now sits at the 99th percentile relative to the past five years. Utilities. The bet appears to be that AI data center demand, the premise on which American Electric Power trades at $65 billion, may not materialize as expected. Meanwhile, names like Bloom Energy, Oracle, and various AI-adjacent plays are showing up on heavily-shorted lists. Hedge funds aren’t yet betting against Nvidia directly, but they’re circling the weaker members of the herd.
There’s a certain irony here that Hooker captures well. Academia was effectively priced out of meaningful AI research by the compute arms race. The explosion in necessary compute “marginalized academia from meaningfully participating in AI progress.” Industry labs stopped publishing to preserve commercial advantage. Now, as scaling hits diminishing returns, the skills that matter shift back toward algorithmic cleverness, data quality, and architectural innovation. Things that don’t require a billion-dollar data center. If you got priced out of the game, the game may be coming back to you. Hooker writes,
The less reliable gains from compute makes our purview as computer scientists interesting again
The quiet tell is how frontier labs are actually behaving. Major players are now incorporating classical symbolic tools, things like Python interpreters and code execution, into LLM pipelines. These symbolic components run on CPUs, not GPUs. Ilya Sutskever, coauthor of the 2012 ImageNet paper and OpenAI cofounder, publicly stated that
We need to go back to the age of research
Shorting the scaling thesis has been a widow-maker trade for the better part of three years. Nvidia is up roughly 800% since 2022. As I’ve written before, the market can remain irrational longer than you can remain solvent, and that applies to both directions. OpenAI reportedly burns around $3 billion monthly with a $40 billion funding round implying perhaps 13 months of runway. If the next mega-round prices down or requires distressed terms, that’s your signal. Until then, the thesis may be directionally correct on the technical limitations while the timing remains treacherous.
We can only see a short distance ahead, but we can see plenty there that needs to be done.
As Alan Turing put it, and Hooker quotes approvingly. The scaling era produced real capabilities alongside real capital misallocation. What comes next is genuinely uncertain. That uncertainty cuts both ways.